是不是程序员总会遇到一个瓶颈期,觉得自己没有进步了,该怎么解决?
这问题不光你碰到,很多知名大公司早就面对过了,看看华为怎么解决的,
人家是站在企业文化的高度上来解决,不管内训还是办公室的墙上都有句反复提及的格言,叫做:
简单的事情重复做,你就是专家。
重复的事情用心做,你就是赢家。
整个公司/部门层面上,把这种观念贯(hu)彻(you)下去,你的问题将迎刃而解。
为啥呢?公司目标和个人目标的差异性问题,公司不是学校,最大的目标是挣钱,这是对所有人负责的大目标。再此基础上,最好的时候,两者是重合的,但不是一直都能重合,更不能 100%的重合,二者本质上是矛盾的。主管当然需要协调让两个目标重叠部分增多,然而根本上来讲,你不可能彻底解决这个问题。
二者重叠度下降难以统一时,员工会选择离职,或者能动性下降。公司目标不能随意改变,作为主管能做只有鼓励员工自学加深岗位相关知识的理解,帮员工调岗,更换工作内容让他从事更重要或者新的工作;然而缺乏锻炼机会的自学是有限的,调岗换工作内容并非容易操作之事,所以对于这些大公司而言,最有效的就是通过文化和思想工作改(xi)变(nao)员工的认识。
所以,主管碰到这类问题再原地死磕通常是没辙的,平时看看励志书也不是绝对没用的。
什么工匠精神,什么拥抱变化,什么专注之类的流行词汇,平时也要及时掌握,深入理解
出门请右转,仔细阅读:成功法则(一):简单的事情重复做、重复的事情用心做
还有该说法的姐妹篇《机会总是留给有准备的人》,搭配始用效果最佳,后者我再一篇文章里展开过:
做主程序员是怎样的体验?
只能帮你到这里了。

哈希表性能优化的方法有很多,比如:
- 使用双 hash 检索冲突
- 使用开放+封闭混合寻址法组织哈希表
- 使用跳表快速定位冲突
- 使用 LRU 缓存最近访问过的键值,不管表内数据多大,短时内访问的总是那么几个
- 使用更好的分配器来管理 keyvaluepair 这个节点对象
上面只要随便选两条你都能得到一个比 unordered_map 快不少的哈希表,类似的方法还有很多,比如使用除以质数来归一化哈希值(x86下性能最好,整数除法非常快,但非x86就不行了,arm还没有整数除法指令,要靠软件模拟,代价很大)。
哈希表最大的问题就是过分依赖哈希函数得到一个正态分布的哈希值,特别是开放寻址法(内存更小,速度更快,但是更怕哈希冲突),一旦冲突多了,或者 load factor 上去了,性能就急剧下降。
Python 的哈希表就是开放寻址的,速度是快了,但是面对哈希碰撞攻击时,挂的也是最惨的,早先爆出的哈希碰撞漏洞,攻击者可以通过哈希碰撞来计算成千上万的键值,导致 Python / Php / Java / V8 等一大批语言写成的服务完全瘫痪。
后续 Python 推出了修正版本,解决方案是增加一个哈希种子,用随机数来初始化它,这都不彻底,开放寻址法对hash函数的好坏仍然高度敏感,碰到特殊的数据,性能下降很厉害。
经过最近几年的各种事件,让人们不得不把目光从“如何实现个更快的哈希表”转移到 “如何实现一个最不坏的哈希表”来,以这个新思路重新思考 hash 表的设计。
哈希表定位主要靠下面一个操作:
index_pos = hash(key) % index_size;
来决定一个键值到底存储在什么地方,虽然 hash(key) 返回的数值在 0-0xffffffff 之前,但是索引表是有大小限制的,在 hash 值用 index_size 取模以后,大量不同哈希值取模后可能得到相同的索引位置,所以即使哈希值不一样最终取模后还是会碰撞。
第一种思路是尽量避免冲突,比如双哈希,比如让索引大小 index_size 保持质数式增长,但是他们都太过依赖于哈希函数本身;所以第二种思路是把注意力放在碰撞发生了该怎么处理上,比如多层哈希,开放+封闭混合寻址法,跳表,封闭寻址+平衡二叉树。
优化方向
今天我们就来实现一下最后一种,也是最彻底的做法:封闭寻址+平衡二叉树,看看最终性能如何?能否达到我们的要求?实现起来有哪些坑?其原理简单说起来就是,将原来封闭寻址的链表,改为平衡二叉树:
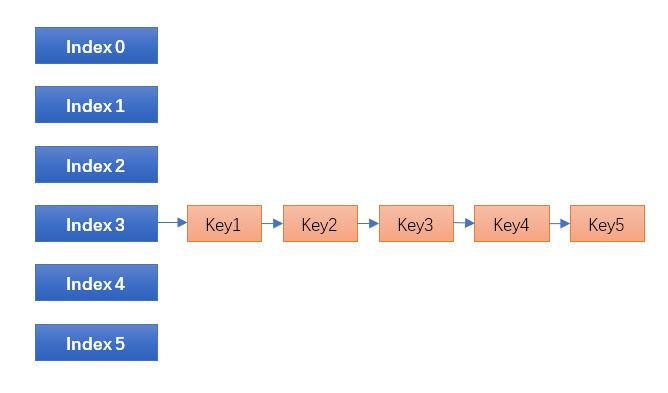
传统的封闭寻址哈希表,也是 Linux / STL 等大部分哈希表的实现,碰到碰撞时链表一长就挂掉,所谓哈希表+平衡二叉树就是:
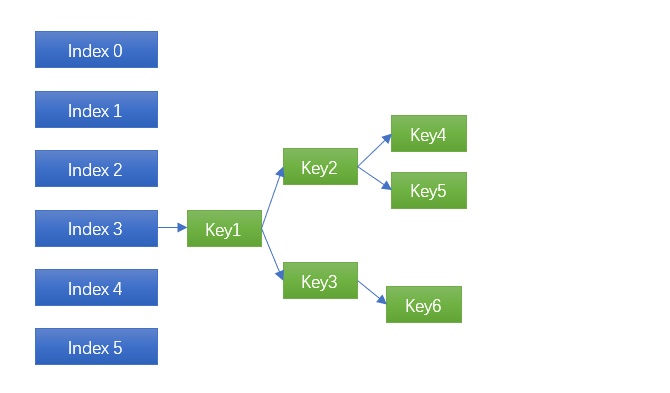
将原来的链表(有序或者无序)换成平衡二叉树,这是复杂度最高的做法,同时也是最可靠的做法。发生碰撞时能将时间复杂度由 O(N) 降低到 O(logN),10个节点,链表的复杂度就是 10,而使用平衡二叉树的复杂度是 3;100个节点前者的时间是100,后者只有6.6 越往后差距约明显。
面临问题
树表混合结构(哈希表+平衡二叉树)的方法,Hash table – Wikipedia 上面早有说明,之所以一直没有进入各大语言/SDK的主流实现主要有四个问题:
- 比起封闭寻址(STL,Java)来讲,节点少时,维持平衡(旋转等)会比有序链表更慢。
- 比起开放寻址(python,v8实现)来讲,内存不紧凑,缓存不够友好。
- 占用更多内存:一个平衡二叉树节点需要更多指针。
- 设计比其他任何哈希表都要复杂。
所以虽然早就有人提出,但是一直都是一个边缘方法,并未进入主流实现。而最近两年随着各大语言暴露出来的各种哈希碰撞攻击,和原有设计基本无力应对坏一些的情况,于是又开始寻求这种树表混合结构是否还有优化的空间。
先来解决第一个问题,如果二叉树节点只有3-5个,那还不如使用有序链表,这是公认的事实,Java 8 最新实现的树表混合结构里,引入了一个 TREEIFY_THRESHOLD = 8 的常量,同一个索引内(或者叫同一个桶/slot/bucket内),冲突键值小于 8 的,使用链表,大于这个阈值时当前 index 内所有节点进行树化操作(treeify)。
Java 8 靠这个方法有效的解决了第一个问题和第三个问题,最终代替了原有 java4-7 一直在使用的 HashMap 老实现,那么我们要使用 Java 8 的方法么?
不用,今天我们换种实现。
Read more…
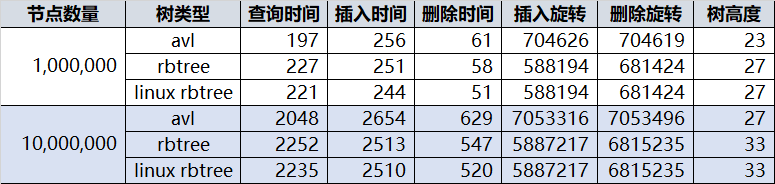
网上对 AVL被批的很惨,认为性能不如 rbtree,这里给 AVL 树平反昭雪。最近优化了一下我之前的 AVL 树,总体跑的和 linux 的 rbtree 一样快了:
他们都比 std::map 快很多(即便使用动态内存分配,为每个新插入节点临时分配个新内存)。
项目代码在:skywind3000/avlmini
其他 AVL/RBTREE 评测也有类似的结论,见:STL AVL Map
谣言1:RBTREE的平均统计性能比 AVL 好
统计下来一千万个节点插入 AVL 共旋转 7053316 次(先左后右算两次),RBTREE共旋转 5887217 次,RBTREE看起来少是吧?应该很快?但是别忘了 RBTREE 再平衡的操作除了旋转外还有再着色,每次再平衡噼里啪啦的改一片颜色,父亲节点,叔叔,祖父,兄弟节点都要访问一圈,这些都是代价,再者平均树高比 AVL 高也成为各项操作的成本。
谣言2:RBTREE 一般情况只比 AVL 高一两层,这个代价忽略不计
纯粹谣言,随便随机一下,一百万个节点的 RBTREE 树高27,和一千万个节点的 AVL树相同,而一千万个节点的 RBTREE 树高 33,比 AVL 多了 6 层,这还不是最坏情况,最坏情况 AVL 只有 1.440 * log(n + 2) – 0.328, 而 RBTREE 是 2 * log(n + 1),也就是说同样100万个节点,AVL最坏情况是 28 层,rbtree 最坏可以到 39 层。
谣言3:AVL树删除节点是需要回溯到根节点
我以前也是这么写 AVL 树的,后来发现根据 AVL 的定义,可以做出两个推论,再平衡向上回溯时:
插入更新时:如当前节点的高度没有改变,则上面所有父节点的高度和平衡也不会改变。
删除更新时:如当前节点的高度没有改变且平衡值在 [-1, 1] 区间,则所有父节点的高度和平衡都不会改变。
根据这两个推论,AVL的插入和删除大部分时候只需要向上回溯一两个节点即可,范围十分紧凑。
谣言4:虽然二者插入一万个节点总时间类似,但是rbtree树更平均,avl有时很快,有时慢很多,rbtree 只需要旋转两次重新染色就行了,比 avl 平均
完全说反了,avl是公认的比rbtree平均的数据结构,插入时间更为平均,rbtree才是不均衡,有时候直接插入就返回了(上面是黑色节点),有时候插入要染色几个节点但不旋转,有时候还要两次旋转再染色然后递归到父节点。该说法最大的问题是以为 rbtree 插入节点最坏情况是两次旋转加染色,可是忘记了一条,需要向父节点递归,比如:当前节点需要旋转两次重染色,然后递归到父节点再旋转两次重染色,再递归到父节点的父节点,直到满足 rbtree 的5个条件。这种说法直接把递归给搞忘记了,翻翻看 linux 的 rbtree 代码看看,再平衡时那一堆的 while 循环是在干嘛?不就是向父节点递归么?avl和rbtree 插入和删除的最坏情况都需要递归到根节点,都可能需要一路旋转上去,否则你设想下,假设你一直再树的最左边插入1000个新节点,每次都想再局部转两次染染色,而不去调整整棵树,不动根节点,可能么?只是说整个过程avl更加平均而已。
比较结论
Read more…
Recent Comments