kNN 的花式用法
April 17th, 2019
1 comment
kNN (k-nearest neighbors)作为一个入门级模型,因为既简单又可靠,对非线性问题支持良好,虽然需要保存所有样本,但是仍然活跃在各个领域中,并提供比较稳健的识别结果。
说到这里也许你会讲,kNN 我知道啊,不就是在特征空间中找出最靠近测试样本的 k 个训练样本,然后判断大多数属于某一个类别,那么将它识别为该类别。
这就是书上/网络上大部分介绍 kNN 的说辞,如果仅仅如此,我也不用写这篇文章了。事实上,kNN 用的好,它真能用出一朵花来,越是基础的东西越值得我们好好玩玩,不是么?
第一种:分类
避免有人不知道,还是简单回顾下 kNN 用于分类的基本思想。
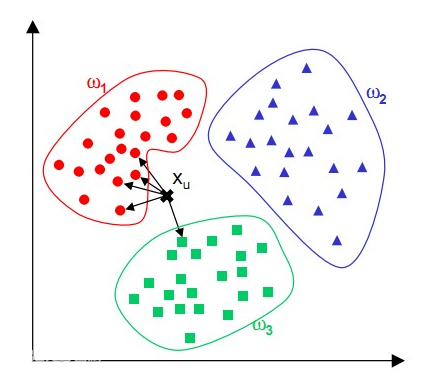
针对测试样本 Xu,想要知道它属于哪个分类,就先 for 循环所有训练样本找出离 Xu 最近的 K 个邻居(k=5),然后判断这 K个邻居中,大多数属于哪个类别,就将该类别作为测试样本的预测结果,如上图有4个邻居是圆形,1是方形,那么判断 Xu 的类别为 “圆形”。
第二种:回归
根据样本点,描绘出一条曲线,使得到样本点的误差最小,然后给定任意坐标,返回该曲线上的值,叫做回归。那么 kNN 怎么做回归呢?

Recent Comments