定点数优化:性能成倍提升
June 20th, 2020
No comments
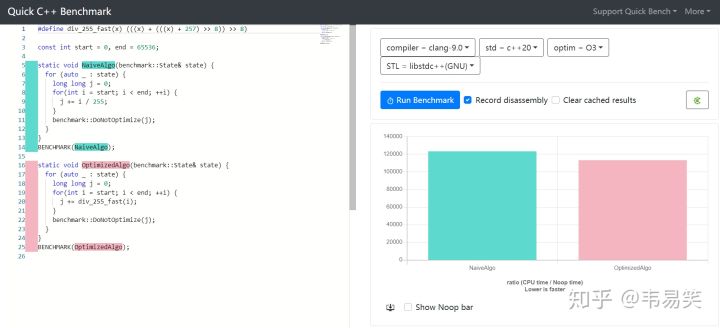
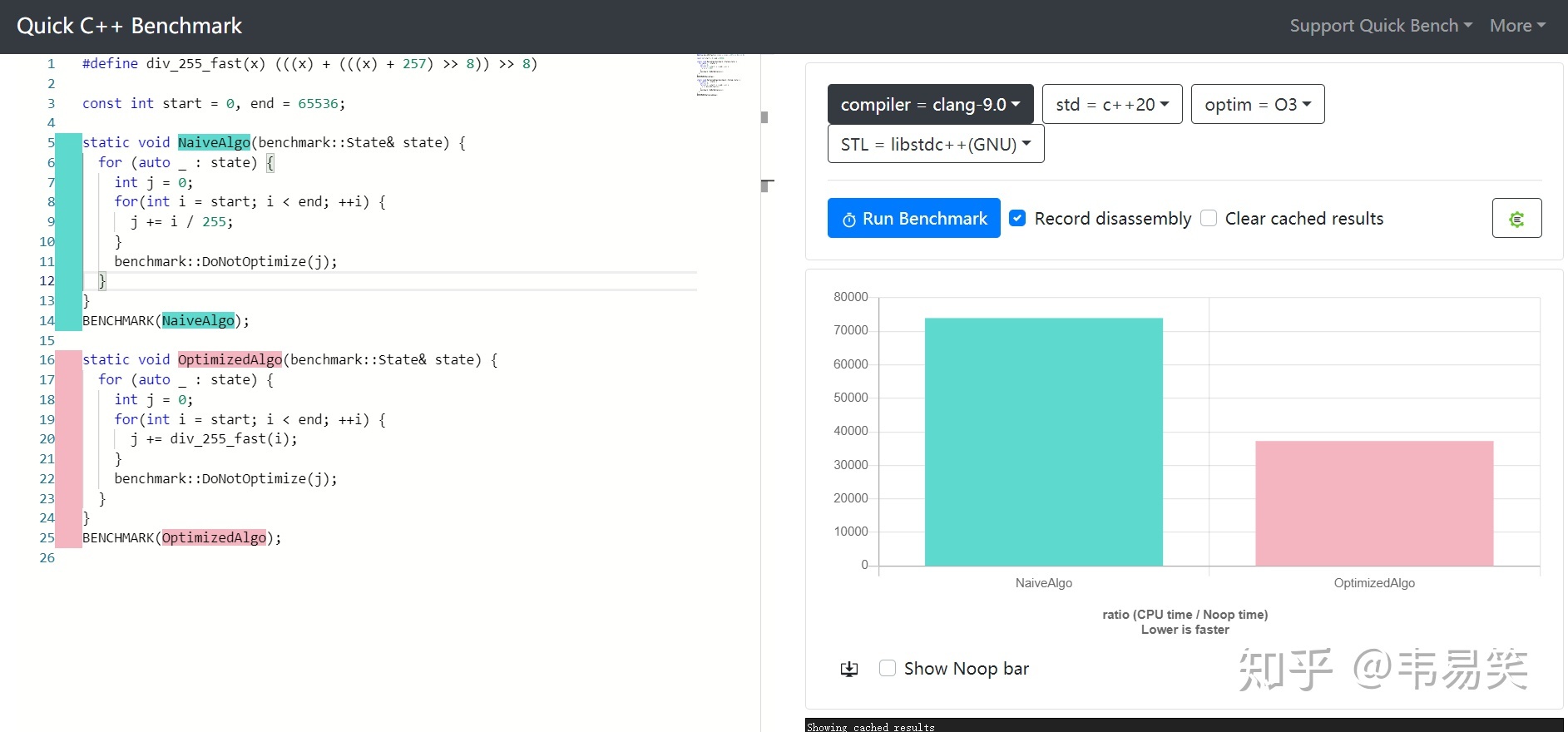
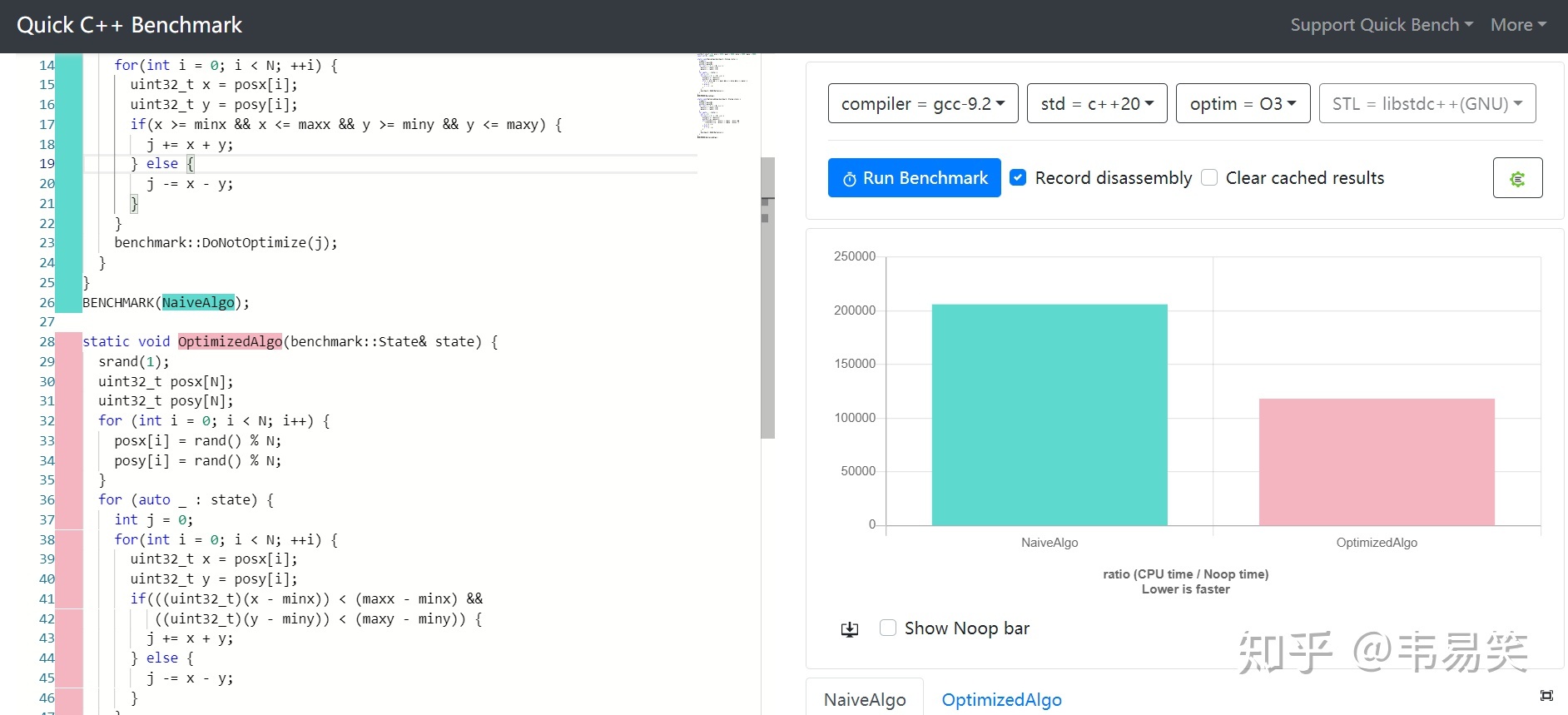
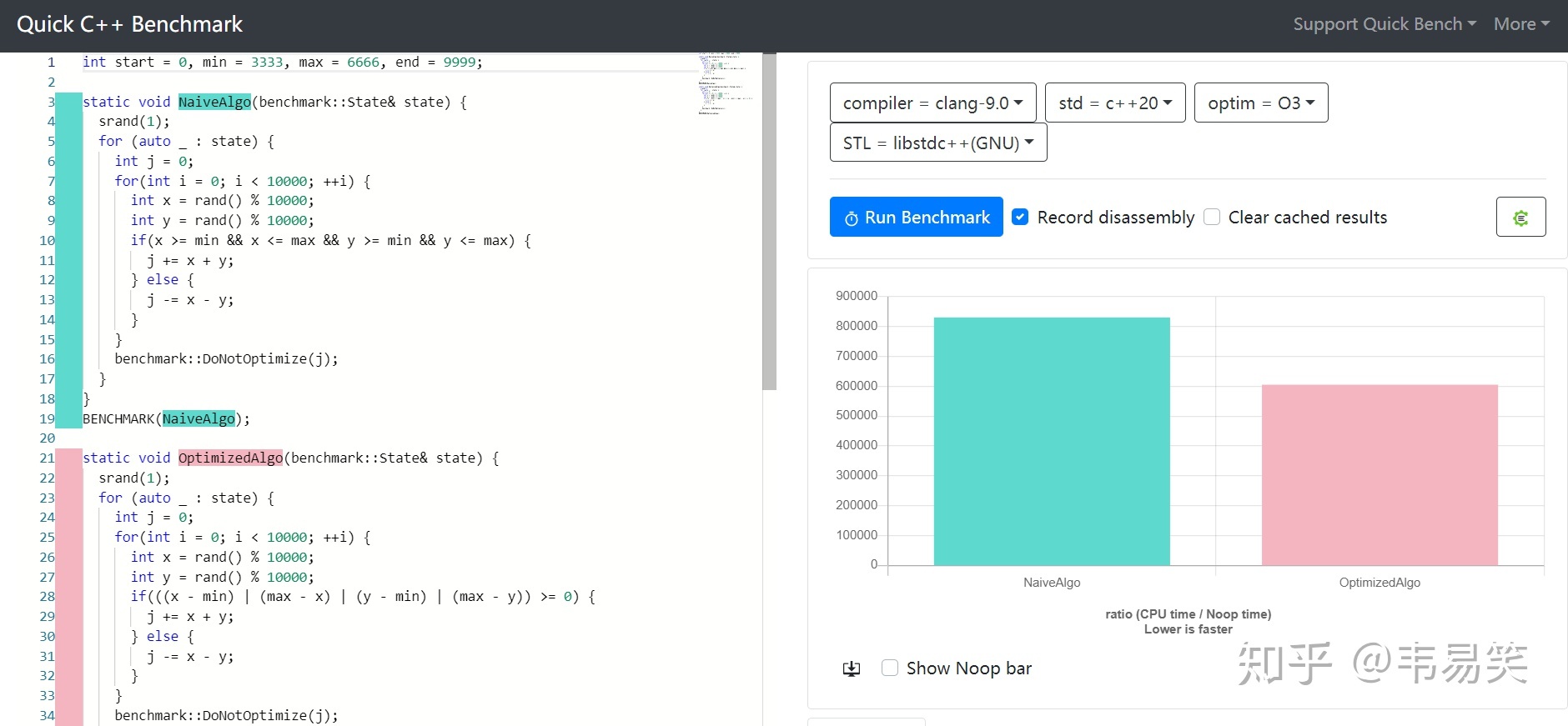
定点数这玩意儿并不是什么新东西,早年 CPU 浮点性能不够,定点数技巧大量活跃于各类图形图像处理的热点路径中。今天 CPU 浮点上来了,但很多情况下整数仍然快于浮点,因此比如:libcario (gnome/quartz 后端)及 pixman 之类的很多库里你仍然找得到定点数的身影。那么今天我们就来看看使用定点数到底能快多少。
简单用一下的话,下面这几行宏就够了:
#define cfixed_from_int(i) (((cfixed)(i)) << 16)
#define cfixed_from_float(x) ((cfixed)((x) * 65536.0f))
#define cfixed_from_double(d) ((cfixed)((d) * 65536.0))
#define cfixed_to_int(f) ((f) >> 16)
#define cfixed_to_float(x) ((float)((x) / 65536.0f))
#define cfixed_to_double(f) ((double)((f) / 65536.0))
#define cfixed_const_1 (cfixed_from_int(1))
#define cfixed_const_half (cfixed_const_1 >> 1)
#define cfixed_const_e ((cfixed)(1))
#define cfixed_const_1_m_e (cfixed_const_1 - cfixed_const_e)
#define cfixed_frac(f) ((f) & cfixed_const_1_m_e)
#define cfixed_floor(f) ((f) & (~cfixed_const_1_m_e))
#define cfixed_ceil(f) (cfixed_floor((f) + 0xffff))
#define cfixed_mul(x, y) ((cfixed)((((int64_t)(x)) * (y)) >> 16))
#define cfixed_div(x, y) ((cfixed)((((int64_t)(x)) << 16) / (y)))
#define cfixed_const_max ((int64_t)0x7fffffff)
#define cfixed_const_min (-((((int64_t)1) << 31)))
typedef int32_t cfixed;
类型狂可以写成 inline 函数,封装狂可以封装成一系列 operator xx,如果需要更高的精度,可以将上面用 int32_t 表示的 16.16 定点数改为用 int64_t 表示的 32.32 定点数。
那么我们找个浮点数的例子优化一下吧,比如 libyuv 中的 ARGBAffineRow_C 函数:
void ARGBAffineRow_C(const uint8_t* src_argb,
int src_argb_stride,
uint8_t* dst_argb,
const float* uv_dudv,
int width) {
int i;
// Render a row of pixels from source into a buffer.
float uv[2];
uv[0] = uv_dudv[0];
uv[1] = uv_dudv[1];
for (i = 0; i < width; ++i) {
int x = (int)(uv[0]);
int y = (int)(uv[1]);
*(uint32_t*)(dst_argb) = *(const uint32_t*)(src_argb + y * src_argb_stride + x * 4);
dst_argb += 4;
uv[0] += uv_dudv[2];
uv[1] += uv_dudv[3];
}
}
这个函数是干什么用的呢?给图像做 仿射变换(affine transformation) 用的,比如 2D 图像库或者 ActionScript 中可以给 Bitmap 设置一个 3×3 的矩阵,然后让 Bitmap 按照该矩阵进行变换绘制:

基本上二维图像所有:缩放,旋转,扭曲都是通过仿射变换完成,这个函数就是从图像的起点(u, v)开始按照步长(du, dv)进行采样,放入临时缓存中,方便下一步一次性整行写入 frame buffer。
这个采样函数有几个特点:
- 运算简单:没有复杂的运算,计算无越界,不需要求什么 log/exp 之类的复杂函数。
- 范围可控:大部分图像长宽尺寸都在 32768 范围内,用 16.16 的定点数即可。
- 转换频繁:每个点的坐标都需要从浮点转换成整数,这个操作很费事。
适合用定点数简单重写一下:(点击 Read more 展开)

Recent Comments