快速范围判断:再来一种新写法
C 语言的魔法数不胜数,我在《C 语言有什么奇技淫巧?》中过给快速范围判断的公式,将:
if (x >= minx && x <= maxx) ...
改做:
if (((x - minx) | (maxx - x)) >= 0) ...
能有一倍的性能提升,我也提到,如果你的数据 99% 都是超出范围的那继续用 && 最快。今天再给大家介绍另外一种新写法,它有更均衡的性能,并且在最坏的情况下,任然表现良好:
if ((unsigned)(x - minx) <= (unsigned)(maxx - minx)) ...
该公式在各种测试数据中能有更均衡的表现,类型安全狂们可以写作:
if (((unsigned)x - (unsigned)minx) <= ((unsigned)maxx - (unsigned)minx)) ...
利用单次无符号整数溢出来减少指令和分支,普通情况,这个公式性能照样快接近一倍:
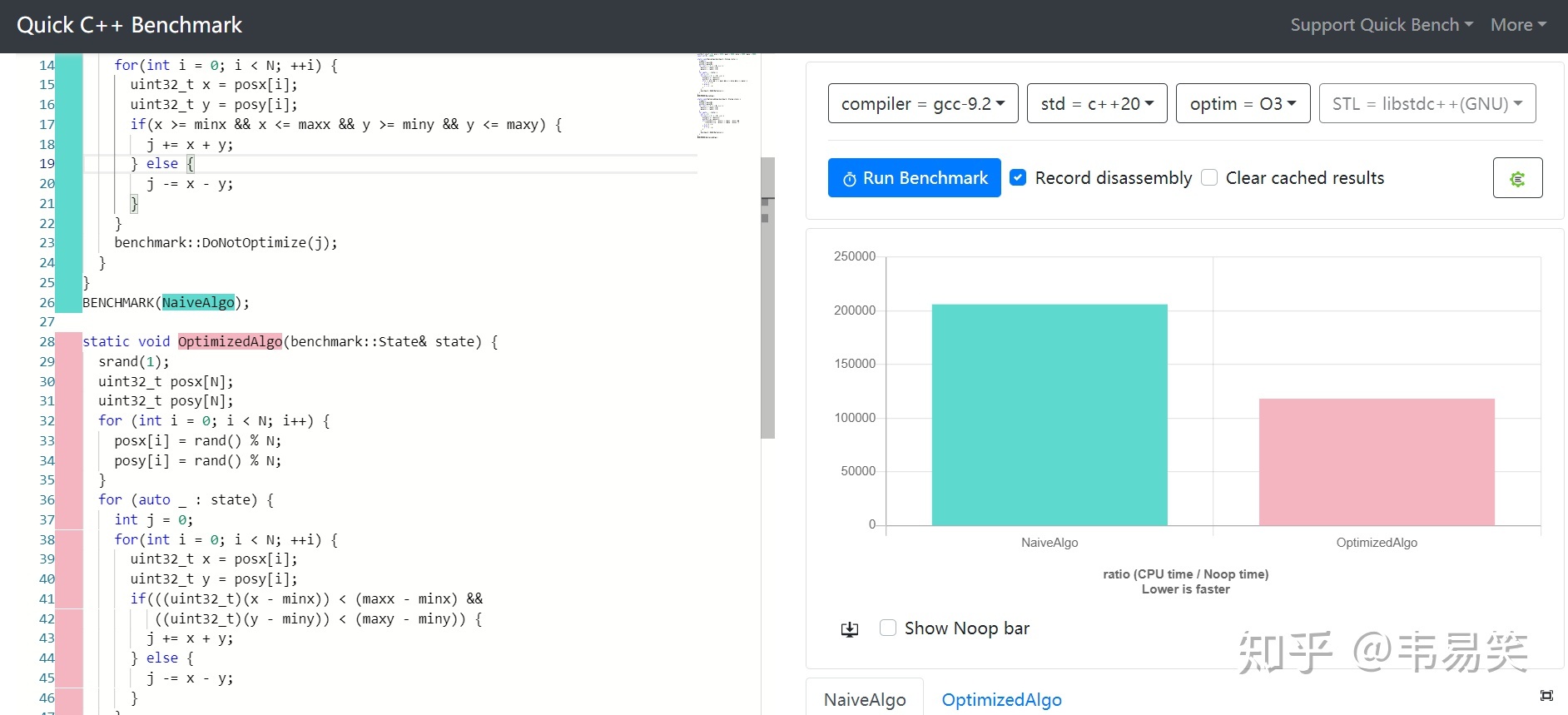
链接:http://quick-bench.com/EbCR9psA3lUEhpn8bYLwVtJ-FWk
为什么说它综合性能最好呢?是不是只实用于某些特殊情况呢?普通情况如何?汇编指令有啥区别?理论依据是啥?是不是只有 x86 可以用,换个平台就不行呢?下面依次回答:
(点击 Read more 展开)
只适合批量范围判断吗?
有人担心编译器批量展开,提前计算 maxx-minx ,认为有新公式只适合批量判断,单次判断每次都要算 maxx – minx,就不一定快了,是这样的么?为了阻挡编译器批量展开,提前计算 maxx – minx,我们将新老判断方法写成单独函数:
int check_range1(int32_t x, int32_t y)
{
return (x >= minx && x <= maxx && y >= miny && y <= maxy)? 1 : 0;
}
int check_range2(int32_t x, int32_t y)
{
return (((uint32_t)(x - minx)) <= ((uint32_t)(maxx - minx)) &&
((uint32_t)(y - miny)) <= ((uint32_t)(maxy - miny)))? 1 : 0;
}
然后用函数指针传递给测试函数,编译器没法知道用的是哪一个了,照样很快:
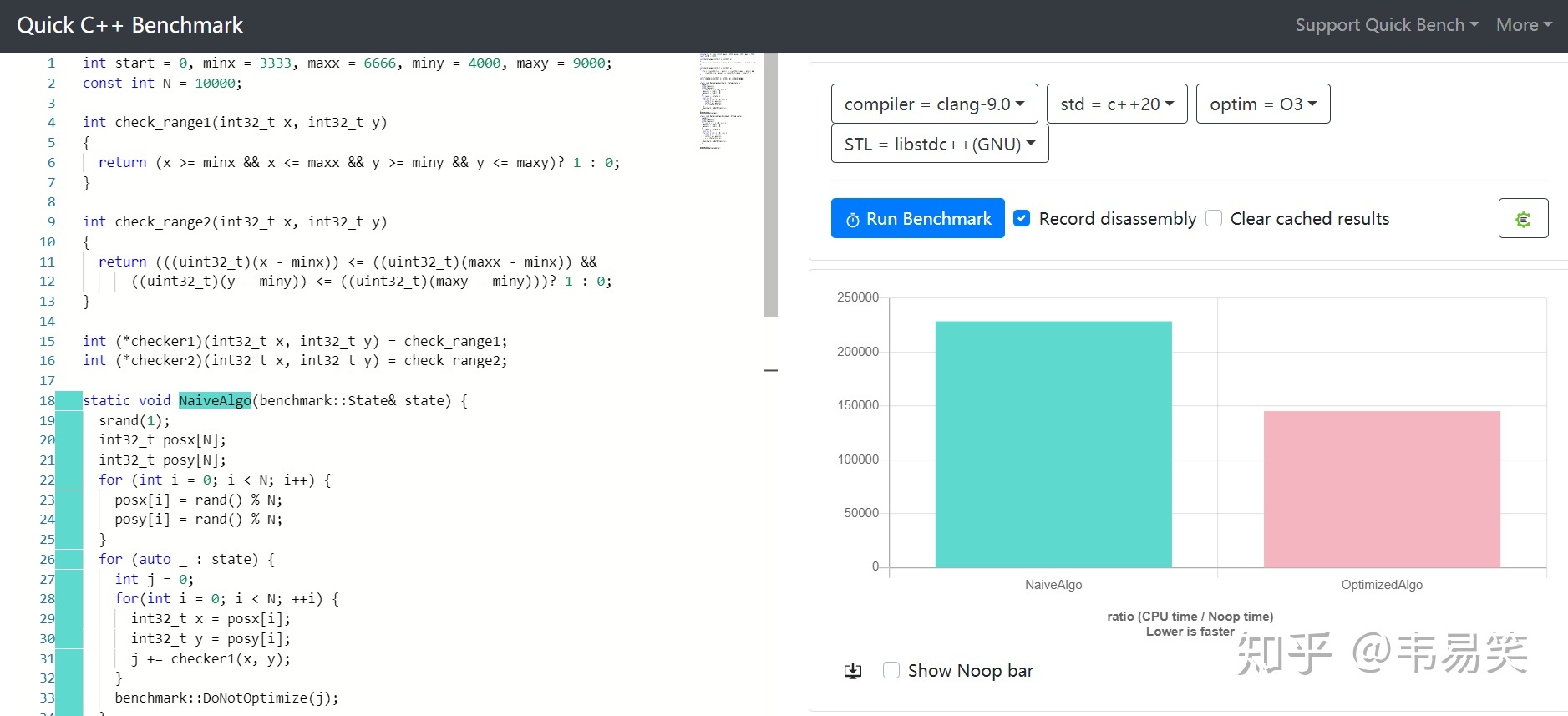
链接:http://quick-bench.com/VCkWBddIhOuqaHgSeXbUwASdtaM
所以该算法同样适合单次判断的情况,但是如果确实是批量判断,该方法由于可以提前计算后半部分,的确可以拿到开头一次计算好,获得更好的性能加持。
范围只能写全局变量么?
有人觉得范围都是全局变量有点写死了,如果当作参数传进去会不会变慢呢?并不会:
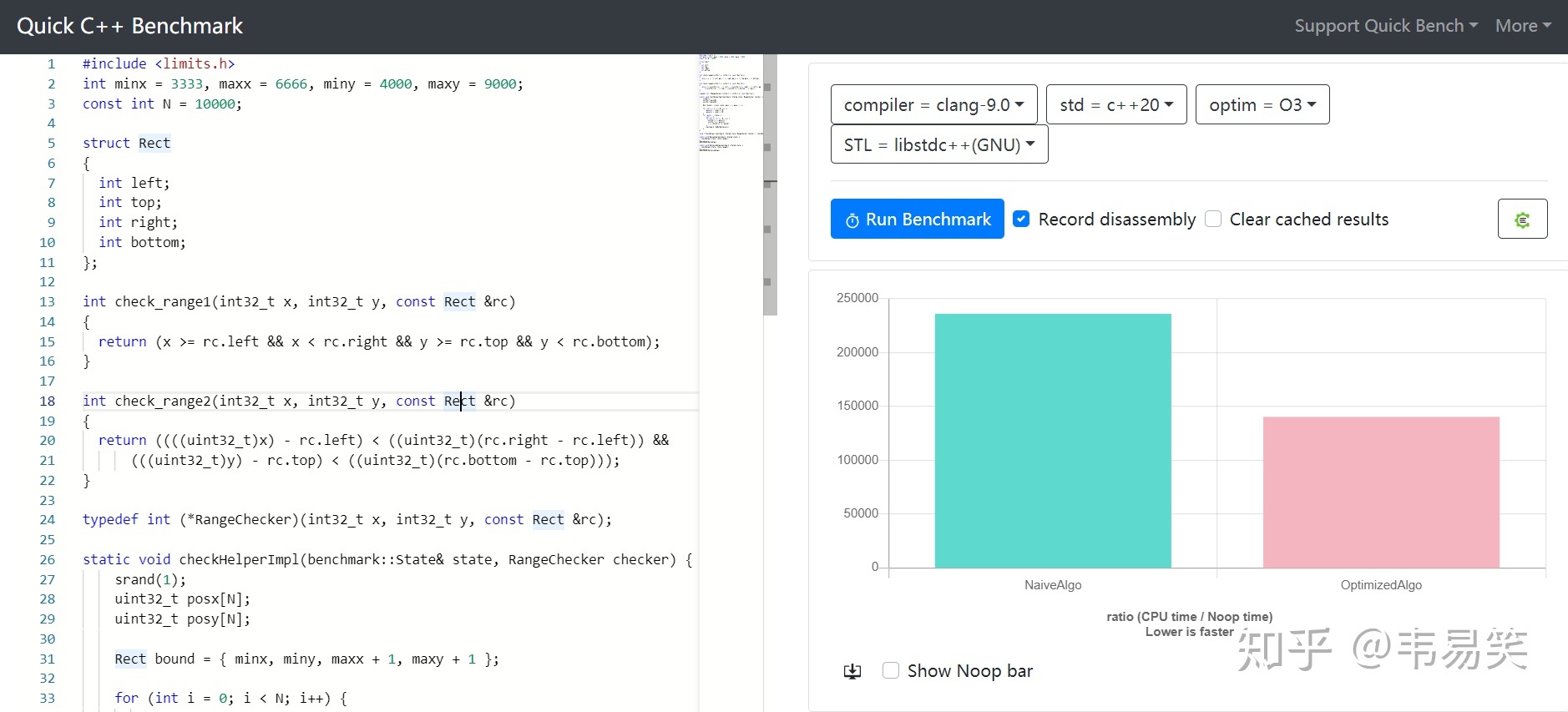
链接:http://quick-bench.com/pRw8SHX52x98E6YuqiYKOZpEjqw
新例子中,定一个矩形 Rect 来表示 x 和 y 的范围,每次同 x, y 一起传递进去。
最坏情况有多坏?
如果 99% 的数据都是范围外的,比如我们把 rand() % N 改为 rand() 去掉后面的 %N 范围限制,或者收缩 min/max 范围,手工把所有数据做成范围外的:
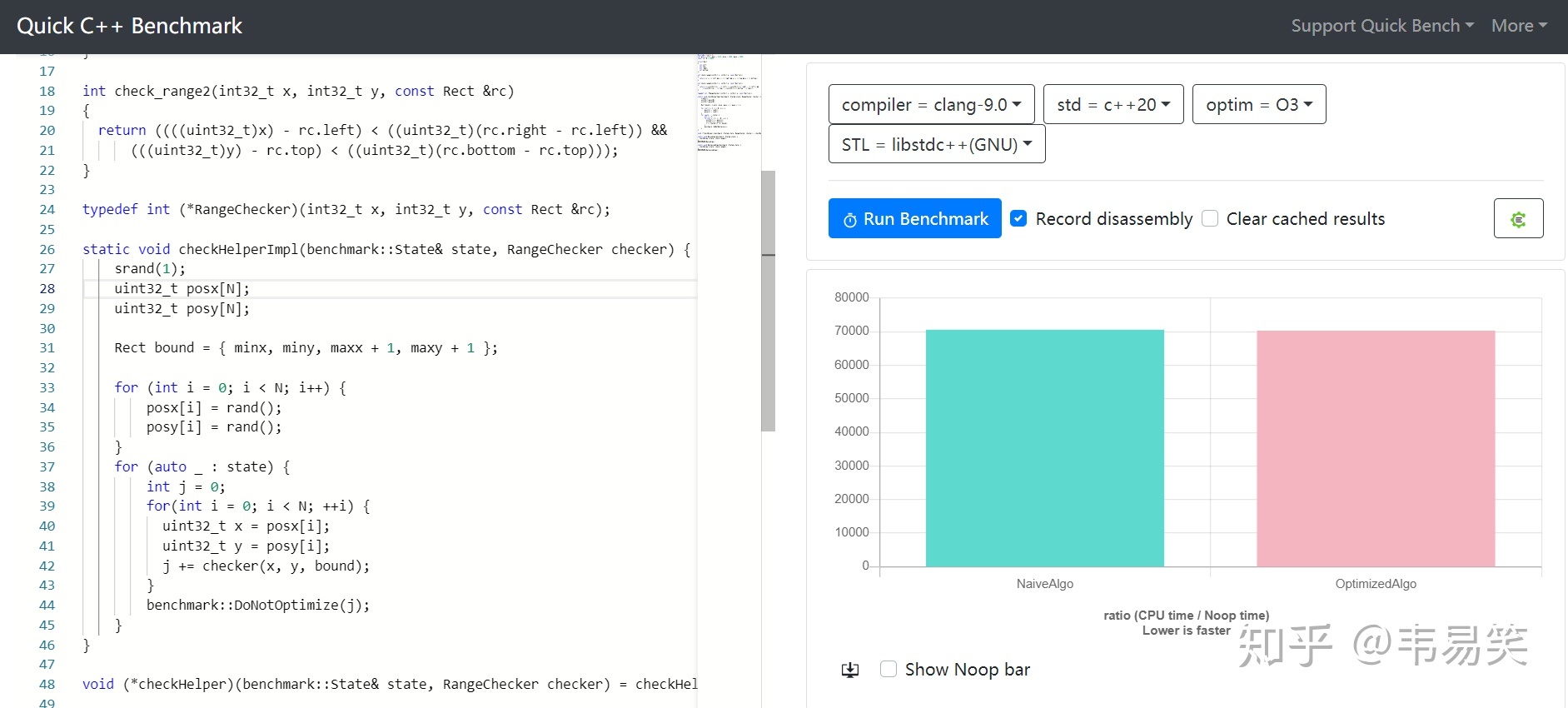
链接:http://quick-bench.com/xWvh59BTMWuxENldScDnycQIesQ
嗯,这就是最坏情况,基本看不出区别来,去掉随机数,把 rand() 直接改为 i 结果也一样的。当然,新方法在最坏情况下比传统 && 还是有略微的差距的,慢了 0.2%,基本可以忽略,除此之外,基本都能快出一倍去。
各种数据范围表现如何?
我们分别改写 minx, maxx, miny, maxy 为不同范围:
百分之 0:minx=0, miny=0, maxx = 0, maxy = 0,所有样本都在范围外:
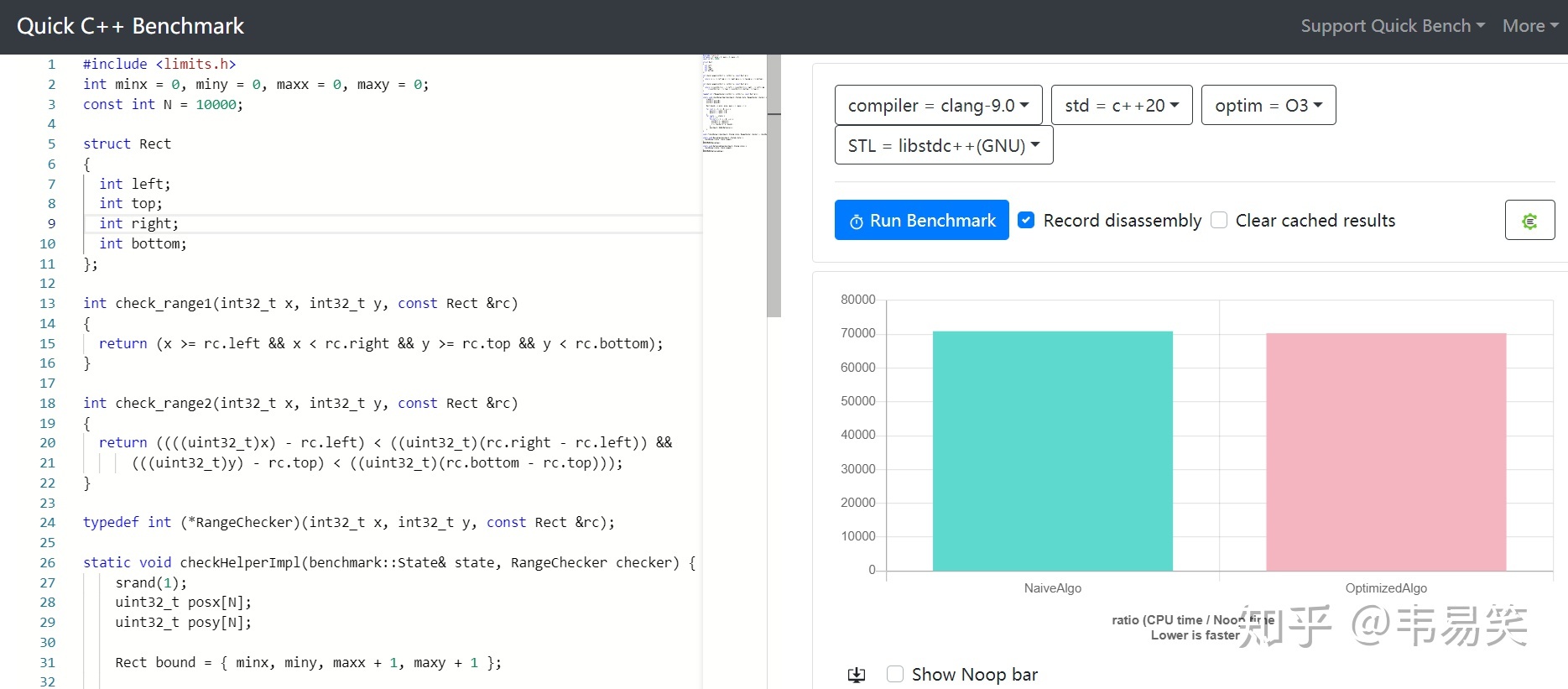
性能几乎相等:http://quick-bench.com/cVmpxgWkEslFoJxm8vC0sIoIpSg
百分之25:minx = 1000, miny = 5000, maxx = 3500, maxy = 7500 少量在范围内:
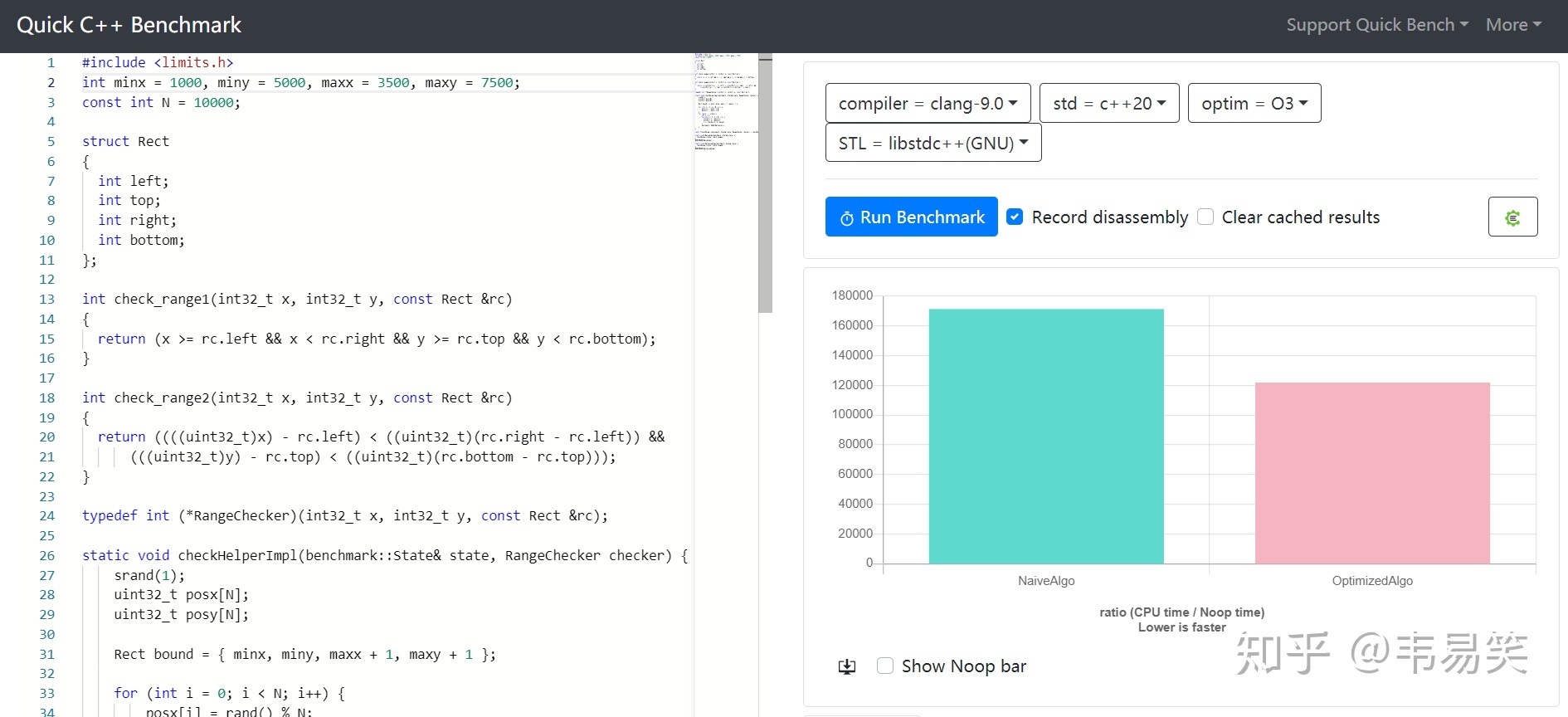
新方法快 40%:http://quick-bench.com/jqlNnQtL6DVLItufTEO17b-Todw
百分之 50:minx = 1000, miny = 4000, maxx = 6000, maxy = 9000 一半一半:

新方法快 30%:http://quick-bench.com/0o0Vy5jKK3h9R8FqHMmp43yu-DY
百分之 75%:minx = 1000, miny = 2000, maxx = 8500, maxy = 9500 大部分范围内:
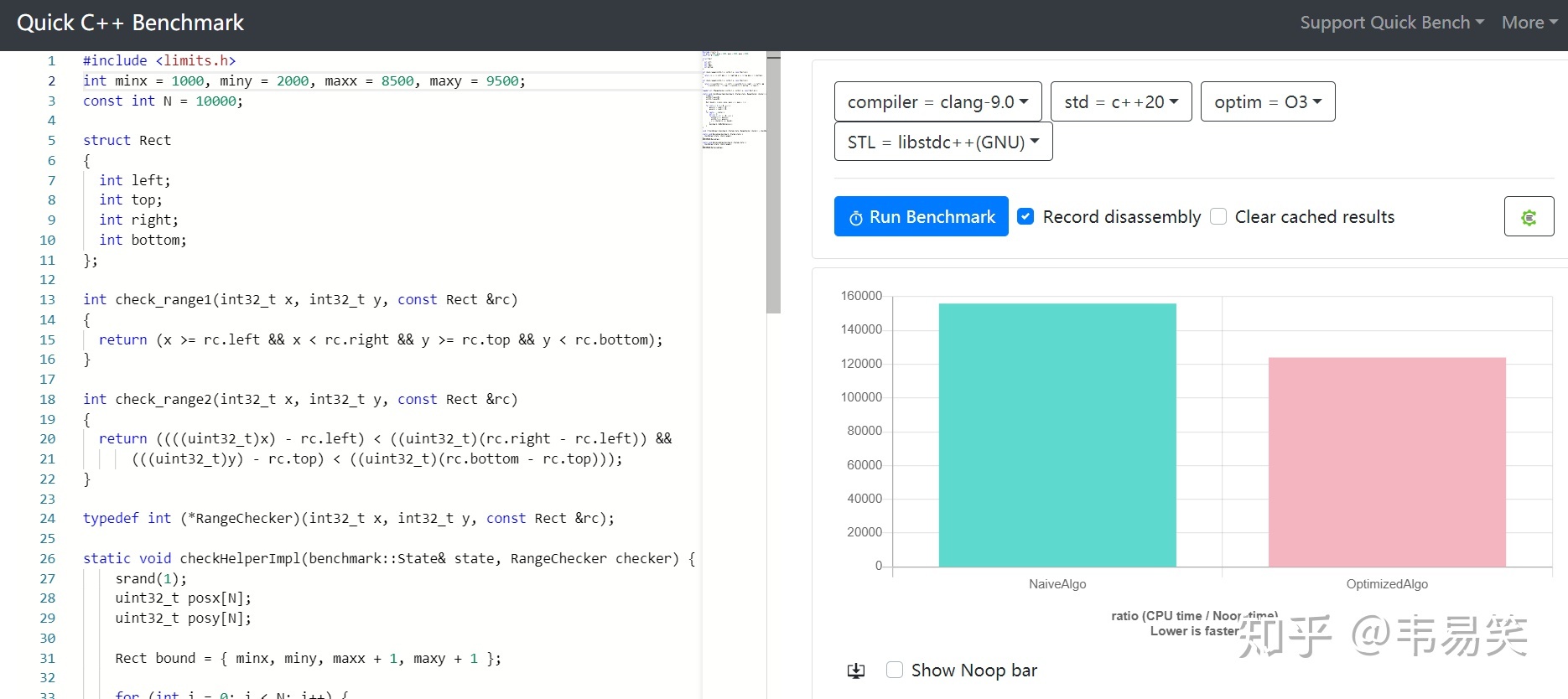
新方法快 30%:http://quick-bench.com/C-UJWmH-CTve697O0Ovbd673cbA
百分之90:minx=100, miny=500, maxx=9100, maxy=9500 少量不在范围:
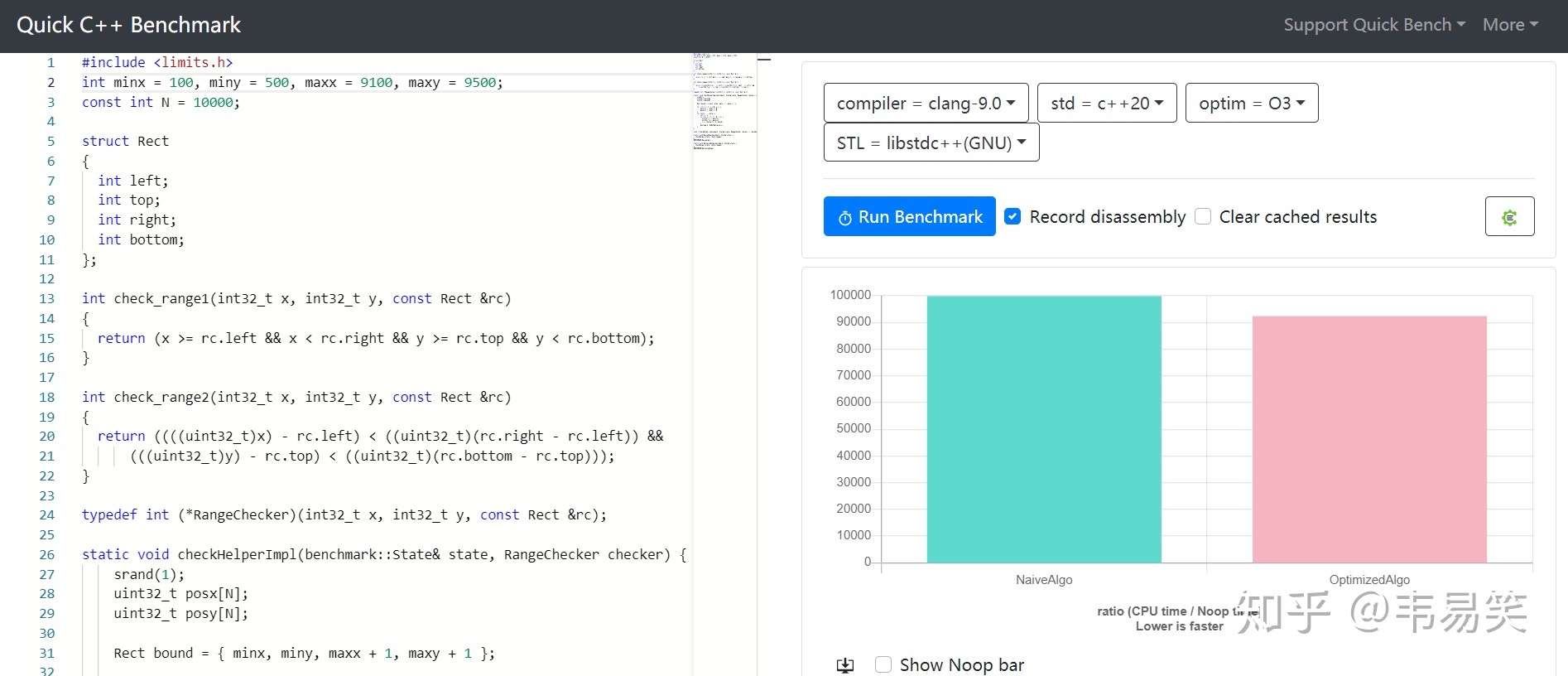
新方法快 10%:http://quick-bench.com/ueByR3TOtXibmItryTpsJzBRjZA
百分之百:minx=0, miny=0, maxx = 9999, maxy=9999, 所有数据都在范围内:
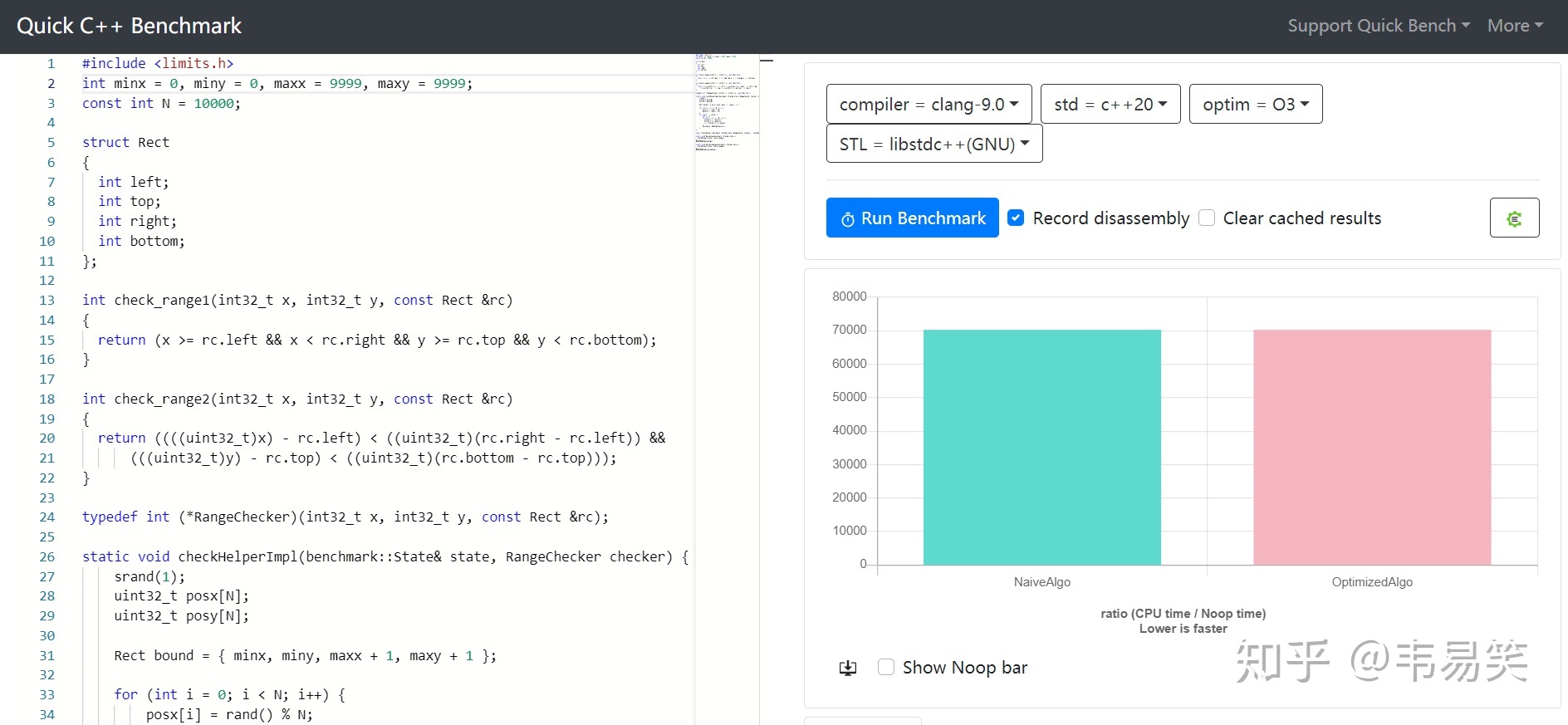
几乎相同:http://quick-bench.com/saRWQ2Xieh89EC5dRq8vMTLPJjY
总结一下:
- 0% 的数据在范围内:几乎相同,新算法略慢 0.2%
- 25% 的数据在范围内:新算法快 40%
- 50% 的数据在范围内:新算法快 30%
- 75% 的数据在范围内:新算法快 30%
- 90% 的数据在范围内:新算法快 10%
- 100% 的数据在范围内:几乎相同,新算法略快 0.04%
可以发现,除了最坏情况,请他所有数据范围都是新方法更快。补充一下,最后所有数据都在范围内时,由于 CPU 分支预测全中,所以看起来差不多。
为什么前面的测试新方法可以快一倍去,这里的测试只快 30%-40% 呢?很简单,额外开销不同,导致看起来优化看起来不一样,但快还是快,慢还是慢。
新快速范围判断和上一版的区别?
新版本公式用的指令数量和占用周期数比第一个版本更少,表现更平均,最坏情况没那么坏,最好情况也没第一个版本那么好,但大部分情况都比 && 快不少。
新方法为什么会快?
首先新方法生成的指令更少:
int range_check1(int v, int min, int max)
{
return v >= min && v < max;
}
int range_check2(int v, int min, int max)
{
return (unsigned) (v - min) < (max - min);
}
对于简单的调用求值, gcc -O3 生成的指令是:
range_check1(int, int, int):
cmp edi, esi
mov r8d, edx
setge dl
xor eax, eax
cmp edi, r8d
setl al
and eax, edx
ret
range_check2(int, int, int):
sub edi, esi
sub edx, esi
xor eax, eax
cmp edi, edx
setb al
ret
skylake 下面:
- mov: latency=0-1cc, thoughput=0.25cc
- add/sub/xor/and: latency=1cc, thoughput=0.25cc
- cmp:latency=1cc, thoughput=0.5cc
- setcc: latency=1cc, thoughput=1cc
延迟代表指令需要的执行周期,吞吐代表指令能够并行执行的情况,0.25cc 代表一个周期内允许四条该指令并行运行,可以看得出因为运算结果简单,现在的编译器都是直接条件指令 setxx 来进行运算的,但是任然是新方法的周期更短,并行程度更高。
你换个编译器,比如 vc,或者老的 gcc,没有优化到这里,条件跳转就出来了:
int range_check1(int,int,int)
cmp ecx, edx
jl SHORT $LN3@range_chec
cmp ecx, r8d
jge SHORT $LN3@range_chec
mov eax, 1
ret 0
$LN3@range_chec:
xor eax, eax
ret 0
int range_check2(int,int,int)
xor eax, eax
sub ecx, edx
sub r8d, edx
cmp ecx, r8d
setb al
ret 0
这种情况下,老方法几次条件跳转将会导致清空多级流水线,不管什么处理器都会非常慢。在这些老版本编译器,或者其他平台的编译器下面,新方法会快的更多。
新版编译器会生成条件指令 setxx 似乎可以有效的减分支,但是别高兴的太早,只要情况稍微复杂点,比如 if 里面多做点事情而不是直接返回,那么 setxx 就挂掉了。我们举个比较现实的例子,画点函数的范围判断:
void write_pixel(int x, int y, int c);
void draw_pixel1(int x, int min, int max)
{
if (x >= min && x < max) {
write_pixel(x, x, 0xffffff);
}
}
void draw_pixel2(int x, int min, int max)
{
if ((unsigned) (x - min) < (max - min)) {
write_pixel(x, x, 0xffffff);
}
}
为了分析简单,这里只用了一个变量 x ,判断范围合法后,会调用实际画点函数 write_pixel 来在内存里或者硬件 frame buffer 中写入实际的数值,最新 gcc -O3 下面(clang 类似):
draw_pixel1(int, int, int):
cmp edi, esi
jl .L1
cmp edi, edx
jl .L10
.L1:
ret
.L10:
mov edx, 16777215
mov esi, edi
jmp write_pixel(int, int, int)
draw_pixel2(int, int, int):
mov eax, edi
sub edx, esi
sub eax, esi
cmp eax, edx
jb .L13
ret
.L13:
mov edx, 16777215
mov esi, edi
jmp write_pixel(int, int, int)
这种情况下前面有 2 个分支,后者只有 1 个分支,虽然后面指令数量相同,但是你别比指令数量,加减只要 1 个周期,并且可以并行四条指令同时执行;而条件跳转 jl 即便命中也是2 个周期,并且不可并行执行,如果分支预测失败,多级流水线一刷新,就等死吧。
分支失效有多严重?
不管是 x86 还是 arm,现代 CPU 优化就几个主要方向:分支优化,缓存优化,并行优化,竞争优化。每条指令执行虽然有的只有 1-2 个周期,但这是指在执行单元里耗费的周期数,现在 CPU 都有多级流水线,如 skylake 就有 16 级流水线,每条指令要经过 16 个步骤,分别是:取指令,解码,分配队列位置,依赖分析,乱序处理,调度,等等一系列,最后才是执行和结果写回。没有分支时,每级流水线单周期可以并行处理多条指令,处理完立即交给下一级。但是分支预测如果失效,比如 16 级流水线清空一半,这代价是非常大的。
所以减分支,依然是局部优化的一个重要方向,你并不能什么都依赖编译器,某些分支编译器模式匹配上了可以帮你减,但是写高性能代码,任然需要把这个原则记熟。
其他平台还有效么?
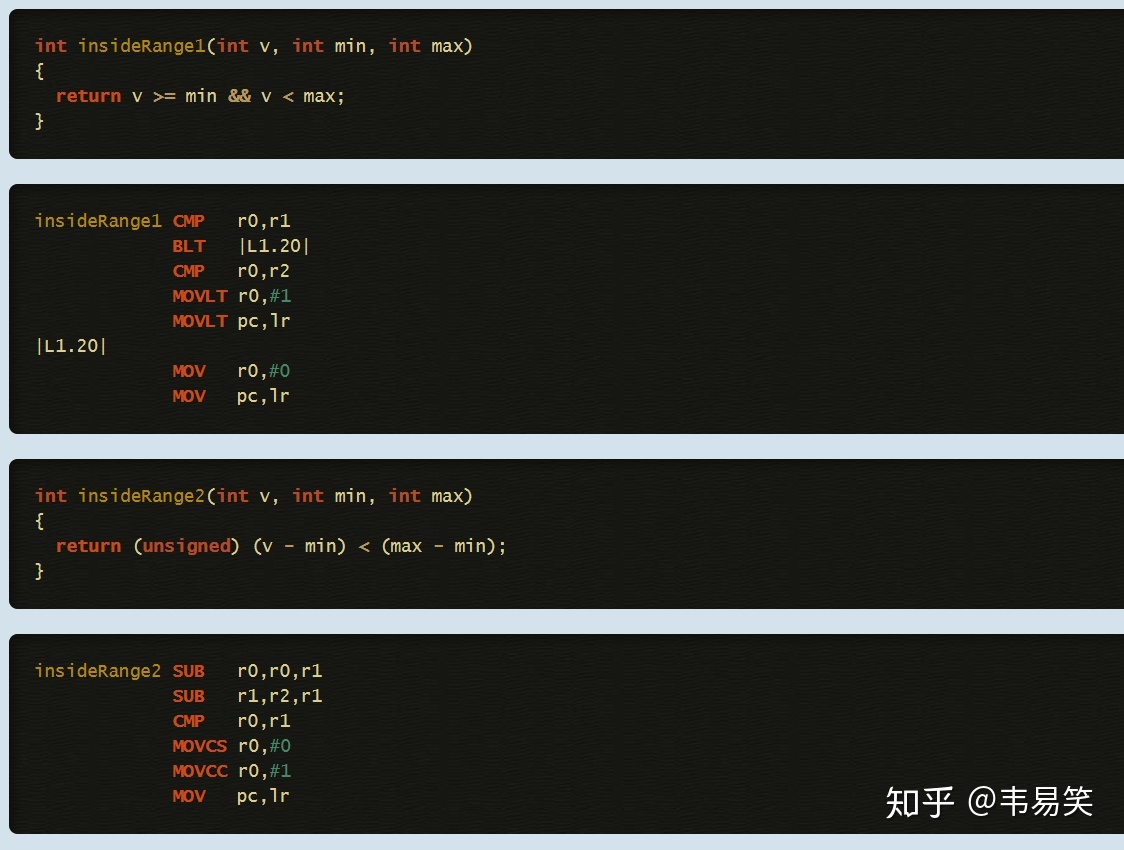
同样有效,上面提到了,现代处理器的共性,这个写法在 《ARM 优化手册》 里提过:
可以等待编译器优化么?
你也可以给编译器提 BUG,但是你基本要等 1-2 年,才能等来一个新的稳定的 toolchain,在此之前,如果你有方法写出快竞争对手两倍的代码,不是很好么?再,比如你做游戏开发,你的代码一会要在 PC 上,一会要在 Playstation 上编译,你并不能决定你用什么编译器,甚至不少平台你用不了最新的编译器。
编译器的优化是模式匹配,代码的组合却是千变万化的,希望有限的模式匹配来覆盖变化无穷的实际代码是不现实的,归根结底还是掌握了解高性能开发的常用思路和方法。
热点路径用汇编优化呢?
有些人觉得 C 代码就老老实实写慢的代码,要快的时候针对不同平台用汇编写如何呢?这是个谬论,你完全不知道你的 C 代码可能被编译到什么平台,且不说大部分程序员写不了比编译器更快的汇编,即便能写,最有效的实践是,先针对通用的 CPU 共性先写出一份通用的足够高效的 C 代码,保证可以任何平台运行,再此基础上,挑选一些个热点路径,针对特定平台来写汇编优化代码。所以不管用不用汇编进行优化,写出足够高效的 C 代码是第一步。
快速范围判断代码不容易理解?
很多人觉得这类优化代码不容易理解,不够直观,宁愿提高可读性,首先,不是提倡你把所有 if 语句都要换掉,而是关键核心路径上使用一下即可,其次,如果你写熟练了,并不会难以理解,一眼看过去就知道干什么,就像熟悉正则表达式的人和不懂的人看同一个正则代码的区别。
最后,代码优化有两个方法,除了复杂变简单外还有简单变复杂,很多高度优化的代码本身就是很难理解的,比如我们映像里的 strlen 是:
size_t strlen(const char *p) {
const char *s = p;
while (*p) p++;
return (size_t)(p - s);
}
很好理解,对吧,一看就懂,而实际 glibc 中,高度优化的 strlen 长这样:
size_t strlen (const char *str) {
const char *char_ptr;
const unsigned long int *longword_ptr;
unsigned long int longword, himagic, lomagic;
for (char_ptr = str; ((unsigned long int) char_ptr & (sizeof (longword) - 1)) != 0; ++char_ptr)
if (*char_ptr == '\0')
return char_ptr - str;
longword_ptr = (unsigned long int *) char_ptr;
himagic = 0x80808080L;
lomagic = 0x01010101L;
if (sizeof (longword) > 4) {
himagic = ((himagic << 16) << 16) | himagic;
lomagic = ((lomagic << 16) << 16) | lomagic;
}
for (;;) {
longword = *longword_ptr++;
if (((longword - lomagic) & ~longword & himagic) != 0) {
const char *cp = (const char *) (longword_ptr - 1);
if (cp[0] == 0) return cp - str;
if (cp[1] == 0) return cp - str + 1;
if (cp[2] == 0) return cp - str + 2;
if (cp[3] == 0) return cp - str + 3;
if (sizeof (longword) > 4) {
if (cp[4] == 0) return cp - str + 4;
if (cp[5] == 0) return cp - str + 5;
if (cp[6] == 0) return cp - str + 6;
if (cp[7] == 0) return cp - str + 7;
}
}
}
}
可以一次性计算 8 个字节内有没有包含 0,平时你写性能不那么敏感的代码当然怎么清晰怎么来,但是你想写性能极致优化的代码,自然要考虑这些局部优化的手段。
全局优化 vs 局部优化?
全局优化强调的是先把程序清晰的写完,再考虑数据流,算法,结构等一系列宏观的东西,否则一开始陷入局部优化了最后可能发现不是重点,这没问题,我从来不否定全局优化的思路。
但是也不要忽视局部优化的两个意义:情况一,再你全局优化已经无能为力的情况下,算法和数据结构都没得弄了,对热点路径使用局部优化手段还能将你的程序性能推上一个新台阶。情况二,再你开发某些高性能 sdk 为其他程序提供支持,本身就没有全局概念的时候,或者你已经预感某函数未来可能会被非常频繁的调用,那么局部优化就是用来研究,在不管其他代码的情况下,如何将某一个函数的性能优化到极致,就像上面的 strlen 实现一样。
所以全局和局部优化两种思路同等有用,觉得只需要一种,并不需要另外一种的认识,都是不够全面的。

Recent Comments