作为 Yacc/Bison 的好搭档 Lex/Flex 是一个很方便的工具,可以通过写几行规则就能生成一个新的词法分析器,大到给你的 parser 提供 token 流,小到解析一个配置文件,都很有帮助;而用 Python 实现一个支持自定义规则的类 Flex/Lex 词法分析器只需要短短 56 行代码,简单拷贝粘贴到你的代码里,让你的代码具备基于可定制规则的词法分析功能。
原理很简单,熟读 Python 文档的同学应该看过 regex module 帮助页面最下面有段程序:
def tokenize(code):
keywords = {'IF', 'THEN', 'ENDIF', 'FOR', 'NEXT', 'GOSUB', 'RETURN'}
token_specification = [
('NUMBER', r'\d+(\.\d*)?'), # Integer or decimal number
('ASSIGN', r':='), # Assignment operator
('END', r';'), # Statement terminator
('ID', r'[A-Za-z]+'), # Identifiers
('OP', r'[+\-*/]'), # Arithmetic operators
('NEWLINE', r'\n'), # Line endings
('SKIP', r'[ \t]+'), # Skip over spaces and tabs
('MISMATCH', r'.'), # Any other character
]
tok_regex = '|'.join('(?P<%s>%s)' % pair for pair in token_specification)
line_num = 1
line_start = 0
for mo in re.finditer(tok_regex, code):
kind = mo.lastgroup
value = mo.group()
column = mo.start() - line_start
if kind == 'NUMBER':
value = float(value) if '.' in value else int(value)
elif kind == 'ID' and value in keywords:
kind = value
elif kind == 'NEWLINE':
line_start = mo.end()
line_num += 1
continue
elif kind == 'SKIP':
continue
elif kind == 'MISMATCH':
raise RuntimeError(f'{value!r} unexpected on line {line_num}')
yield Token(kind, value, line_num, column)
上面这个官方文档里的程序,输入一段代码,返回 token 的:名称、原始文本、行号、列号 等。
它其实已经具备好三个重要功能了:1)规则自定义;2)由上往下匹配规则;3)使用生成器,逐步返回结果,而不是一次性处理好再返回,这个很重要,可以保证语法分析器边分析边指导词法分析器做一些精细化分析。
我们再它的基础上再修改一下,主要补充:
- 支持外部传入规则,而不是像上面那样写死的。
- 规则支持传入函数,这样可以根据结果进行二次判断。
- 更好的行和列信息统计,不依赖 NEWLINE 规则的存在。
- 支持 flex/lex 中的 “忽略”规则,比如忽略空格和换行,或者忽略注释。
- 支持在流末尾添加一个 EOF 符号,某些 parsing 技术需要输入流末尾插入一个名为 \$ 的结束符。
对文档中的简陋例子做完上面五项修改,我们即可得到一个通用的基于规则的词法分析器。
改写后代码很短,只有 56 行:
(点击 more 展开)
Read more…

帧同步可以轻松解决高互动的联网游戏(如格斗,RTS 等)的同步问题,但该方案对延迟很敏感,现在一般省内服务器延迟差不多 10-15ms (1帧),跨省一般 40ms (2-3 帧),在此情况下,使用 Run-Ahead 机制可以有效的掩盖延迟的体感,让用玩家立马看到自己的操作反馈。
该机制有很多其他名字比如:预测回滚(prediction and rollback),或者时间曲力(time warp),名字取的天花乱坠的,很多文章也只是云里雾里说一半天,结果还没说清楚,所以本文打算最简短的句子说清楚这个概念,并给出可以实际操作的实现步骤。
我觉得用 Run-Ahead 这个质朴的名字更容易说明这个算法背后的思想:提前运行,这个概念不光用在游戏同步里,也早已用在游戏模拟器中,为了便于理解,先说一下模拟器中的情况(更简单)。
RetroArch 使用 Run-Ahead 隐藏输入延迟,一般需要设置一下 Run-Ahead 的帧数,比如 0 是关闭,1 是提前运行一帧,2 是提前运行两帧,一般设置用 1 或者 2,不要超过 5,因为太高游戏表现会很奇怪:
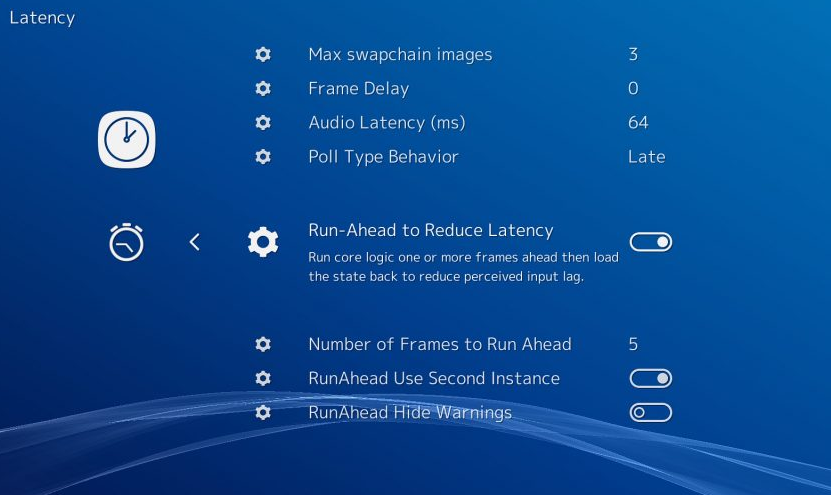
运行时 RetroArch 为每帧保存快照,假定的是用户输入有持续性,那么运行时当前帧使用上一帧用户的输入作为本帧输入(假设 runahead 设置为 1),然后接着往下运行,如果用户新输入来了,一律把它算作当前帧-1 的输入,然后再去对比历史如果和上一帧所尝试假定的输入一致就继续,否则快照回退到上一帧,重新用新的输入去运行,然后再快进到当前帧。
通常手柄或键盘都有 5ms 左右的输入延迟(部分设备如 switch 的 pro 手柄延迟高达 15ms),再加上操作系统处理的延迟,投递到模拟器进程里,从按下到真正开始处理也许也差不多 1 帧的时间了,RetroArch 用这个功能,也只有用户真实输入和预测输入不一致时才会触发,由于间隔很短,所以即使纠正也难看出来,最终在模拟器上达到了物理设备一样的超低延迟体验。
理解了模拟器的 Run-Ahead 实现,其实在帧同步里的原理也就差不多了,无外乎是用远程的旧输入,搭配本地刚采集到的新输入,作为预测帧的输入值,产生新帧,不匹配了再回滚。
帧同步里引入类似 Run-Ahead 的机制,要求游戏最近所有状态都可以被快速保存、复制和恢复,实现有很多种,你可以用状态的反复前进、后退来实现,但是 BUG 率太高了,这里给出一个更简易的实现方式:
(点击 more 展开)
Read more…
最近时间线上又起了一场不大不小的论战,做互联网的人觉得游戏服务端发展很慢,同时互联网技术日新月异,似乎觉得互联网技术领先了游戏后端技术十年,这个结论显然是武断的,几位朋友也已经驳斥的很充分了,游戏服务端的同学实属没必要和这个互联网的人一般见识,本来就此打住也还挺好。
但最近两天事情似乎正在悄悄起变化,时间线上一直看到不停的有人跳出来,清一色的全在说互联网简单,什么做个电商不过就是 CRUD 的话也出来了,看的我也大跌眼镜,过犹不及吧。
今天更是又刷到有几位不管不顾就说什么游戏服务端领先互联网十年什么的,似乎这又要成为了另外一个极端了,那么有几点情况是不是也请正视一下:
1)游戏服务端足够复杂,但是发展太慢,祖传代码修修补补跑个十多年的不要太多。能用固然是好事,但没有新观念的引入,导致可用性和开发效率一直没有太多提升。
2)各自闭门造车,没有形成行业标准与合力,这个项目的代码,很难在另一个项目共享,相互之间缺少支持和协同。
3)互联网后端随便拎出一个服务来(包括各种 C/C++ 基建)大概率都没有游戏服务端复杂,但最近十年日新月异,形成了很强的互相组合互相增强的态势。
我上面指的是互联网基建项目,不是互联网 CRUD,互联网近十年的发展,让其整体可用性,效能,开发效率,都上了很多个台阶,不应一味忽视。
如果继续觉得游戏服务端领先互联网十年可以直接右转了,开放心态的话我也可以多聊一些(点击下方 more 阅读更多):
Read more…
前文《基于 LR(1) 和 LALR 的 Parser Generator》里介绍了春节期间开发的小玩具 LIBLR ,今天春节最后一天,用它跑一个小例子,解析带注释的 json 文件。由于 python 自带 json 库不支持带注释的 json 解析,而 vscode 里大量带注释的 json 没法解析,所以我们先写个文法,保存为 json.txt:
# 定义两个终结符
%token NUMBER
%token STRING
start: value {get1}
;
value: object {get1}
| array {get1}
| STRING {get_string}
| NUMBER {get_number}
| 'true' {get_true}
| 'false' {get_false}
| 'null' {get_null}
;
array: '[' array_items ']' {get_array}
;
array_items: array_items ',' value {list_many}
| value {list_one}
| {list_empty}
;
object: '{' object_items '}' {get_object}
;
object_items: object_items ',' item_pair {list_many}
| item_pair {list_one}
| {list_empty}
;
item_pair: STRING ':' value {item_pair}
;
# 词法:忽略空白
@ignore [ \r\n\t]*
# 词法:忽略注释
@ignore //.*
# 词法:匹配 NUMBER 和 STRING
@match NUMBER [+-]?\d+(\.\d*)?
@match STRING "(?:\\.|[^"\\])*"
有了文法,程序就很短了,50 多行足够:(点击 more 展开)
Read more…
最近处理文本比较多,先前想增强下正则,看来不够用了,有同学推荐了我 Pyl 和 Lark,看了两眼,初看还行,但细看有一些不太喜欢的地方,于是刚好春节几天有空,从头写了一个 LR(1) / LALR 的 Generator,只有一个 LIBLR.py 的单文件,没有其它依赖:
用法很简单,给定文法,返回 Parser:
import LIBLR
# 注意这里是 r 字符串,方便后面写正则
# 所有词法规则用 @ 开头,从上到下依次匹配
grammar = r'''
start: WORD ',' WORD '!';
@ignore [ \r\n\t]*
@match WORD \w+
'''
parser = LIBLR.create_parser(grammar)
print(parser('Hello, World !'))
输出:
Node(Symbol('start'), ['Hello', ',', 'World', '!'])
默认没有加 Semantic Action 的话,会返回一颗带注释的语法分析树(annotated parse-tree)。
支持语义动作(Semantic Action),可以在生成式中用 {name} 定义,对应 name 的方法会在回调中被调用:
import LIBLR
# 注意这里是 r 字符串,方便后面写正则
grammar = r'''
# 事先声明终结符
%token number
E: E '+' T {add}
| E '-' T {sub}
| T {get1}
;
T: T '*' F {mul}
| T '/' F {div}
| F {get1}
;
F: number {getint}
| '(' E ')' {get2}
;
# 忽略空白
@ignore [ \r\n\t]*
# 词法规则
@match number \d+
'''
# 定义语义动作:各个动作由类成员实现,每个方法的
# 第一个参数 rule 是对应的生成式
# 第二个参数 args 是各个部分的值,类似 yacc/bison 中的 $0-$N
# args[1] 是生成式右边第一个符号的值,以此类推
# args[0] 是继承属性
class SemanticAction:
def add (self, rule, args):
return args[1] + args[3]
def sub (self, rule, args):
return args[1] - args[3]
def mul (self, rule, args):
return args[1] * args[3]
def div (self, rule, args):
return args[1] / args[3]
def get1 (self, rule, args):
return args[1]
def get2 (self, rule, args):
return args[2]
def getint (self, rule, args):
return int(args[1])
parser = LIBLR.create_parser(grammar, SemanticAction())
print(parser('1+2*3'))
输出:
(点击 more 查看更多)
Read more…
正则写复杂了很麻烦,难写难调试,只需要两个函数,就能用简单正则组合构建复杂正则:
比如输入一个字符串规则,可以使用 {name} 引用前面定义的规则:
# rules definition
rules = r'''
protocol = http|https
login_name = [^:@\r\n\t ]+
login_pass = [^@\r\n\t ]+
login = {login_name}(:{login_pass})?
host = [^:/@\r\n\t ]+
port = \d+
optional_port = (?:[:]{port})?
path = /[^\r\n\t ]*
url = {protocol}://({login}[@])?{host}{optional_port}{path}?
'''
然后调用 regex_build 函数,将上面的规则转换成一个字典并输出:
# expand patterns in a dictionary
m = regex_build(rules, capture = True)
# list generated patterns
for k, v in m.items():
print(k, '=', v)
结果:
protocol = (?P<protocol>http|https)
login_name = (?P<login_name>[^:@\r\n\t ]+)
login_pass = (?P<login_pass>[^@\r\n\t ]+)
login = (?P<login>(?P<login_name>[^:@\r\n\t ]+)(:(?P<login_pass>[^@\r\n\t ]+))?)
host = (?P<host>[^:/@\r\n\t ]+)
port = (?P<port>\d+)
optional_port = (?P<optional_port>(?:[:](?P<port>\d+))?)
path = (?P<path>/[^\r\n\t ]*)
url = (?P<url>(?P<protocol>http|https)://((?P<login>(?P<login_name>[^:@\r\n\t ]+)(:(?P<login_pass>[^@\r\n\t ]+))?)[@])?(?P<host>[^:/@\r\n\t ]+)(?P<optional_port>(?:[:](?P<port>\d+))?)(?P<path>/[^\r\n\t ]*)?)
用手写直接写是很难写出这么复杂的正则的,写出来也很难调试,而组合方式构建正则的话,可以将小的简单正则提前测试好,要用的时候再组装起来,就不容易出错,上面就是组装替换后的结果。
下面用里面的 url 这个规则来匹配一下:
(点击 more 展开)
Read more…
测试一下 python 的 asyncio 和 gevent 的性能,再和同等 C 程序对比一下,先安装依赖:
pip3 install hiredis gevent
如果是 Linux 的话,可以选择安装 uvloop 的包,可以测试加速 asyncio 的效果。
测试程序:echo_bench_gevent.py
import sys
import gevent
import gevent.monkey
import hiredis
from gevent.server import StreamServer
gevent.monkey.patch_all()
d = {}
def process(req):
# only support get/set
cmd = req[0].lower()
if cmd == b'set':
d[req[1]] = req[2]
return b"+OK\r\n"
elif cmd == b'get':
v = d.get(req[1])
if v is None:
return b'$-1\r\n'
else:
return b'$1\r\n1\r\n'
else:
print(cmd)
raise NotImplementedError()
return b''
def handle(sock, addr):
reader = hiredis.Reader()
while True:
buf = sock.recv(4096)
if not buf:
return
reader.feed(buf)
while True:
req = reader.gets()
if not req:
break
sock.sendall(process(req))
return 0
print('serving on 0.0.0.0:5000')
server = StreamServer(('0.0.0.0', 5000), handle)
server.serve_forever()
测试程序:echo_bench_asyncio.py
(点击 Read more 展开)
Read more…
最近看到米哈游《原神》的客户端安装文件里附带了 KCP 的 LICENSE:
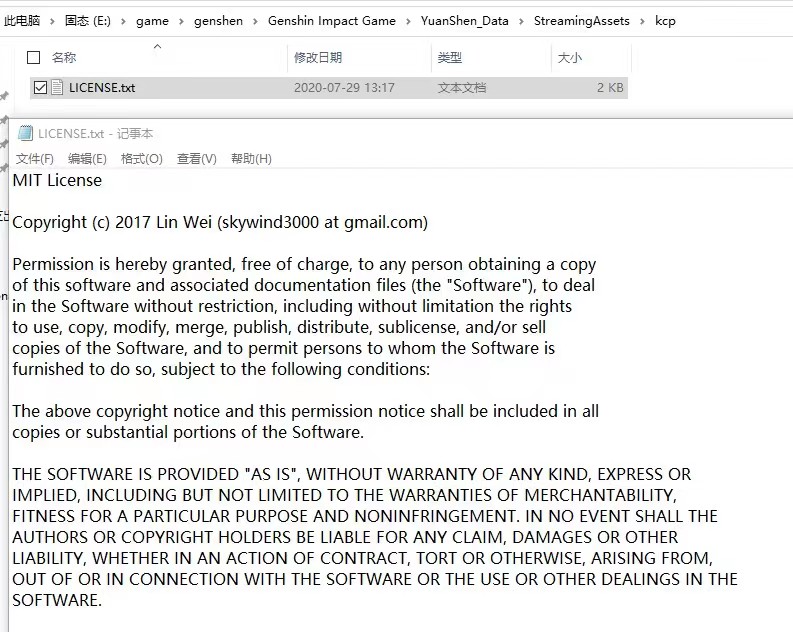
于是找米哈游的同学求证了一下,果然他们在游戏里使用 KCP 来保证游戏消息可以以较低的延迟进行传输,这里还有一篇文章分析了原神使用 KCP 的具体细节:
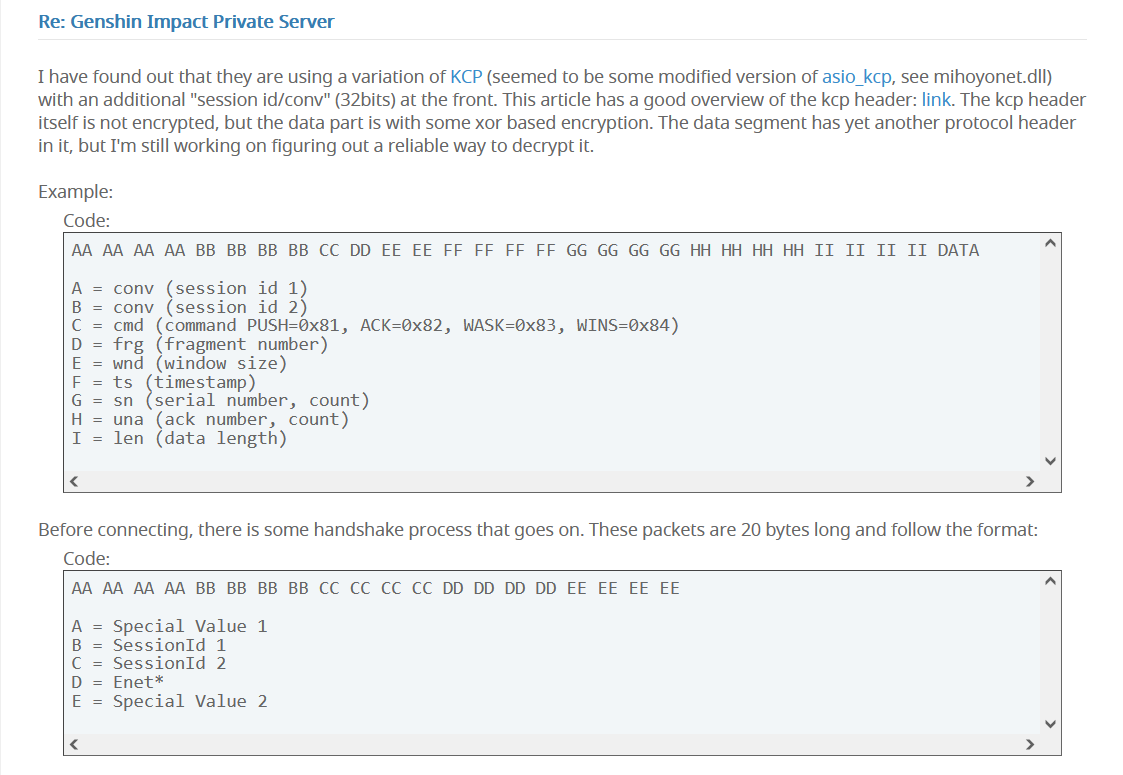
文章见:https://forum.ragezone.com/f861/genshin-impact-private-server-1191004/index7.html
KCP 是我之前开源的一套低延迟可靠传输协议,能够有比 TCP/QUIC 更快的端到端传输效果,适合游戏、音视频以及各类延迟敏感的应用。
欢迎大家尝试:
目前使用 KCP 的商用项目包括不限于:
- 原神:米哈游的《原神》使用 KCP 降低游戏消息的传输耗时,提升操作的体验。
- SpatialOS: 大型多人分布式游戏服务端引擎,BigWorld 的后继者,使用 KCP 加速数据传输。
- 西山居:使用 KCP 进行游戏数据加速。
- CC:网易 CC 使用 kcp 加速视频推流,有效提高流畅性
- BOBO:网易 BOBO 使用 kcp 加速主播推流
- UU:网易 UU 加速器使用 KCP/KCPTUN 经行远程传输加速。
- 阿里云:阿里云的视频传输加速服务 GRTN 使用 KCP 进行音视频数据传输优化。
- 云帆加速:使用 KCP 加速文件传输和视频推流,优化了台湾主播推流的流畅度。
- 明日帝国:Game K17 的 《明日帝国》,使用 KCP 加速游戏消息,让全球玩家流畅联网
- 仙灵大作战:4399 的 MOBA游戏,使用 KCP 优化游戏同步
KCP 成功的运行在多个用户规模上亿的项目上,为他们提供了更加灵敏和丝滑网络体验。
Recent Comments