作为 Yacc/Bison 的好搭档 Lex/Flex 是一个很方便的工具,可以通过写几行规则就能生成一个新的词法分析器,大到给你的 parser 提供 token 流,小到解析一个配置文件,都很有帮助;而用 Python 实现一个支持自定义规则的类 Flex/Lex 词法分析器只需要短短 56 行代码,简单拷贝粘贴到你的代码里,让你的代码具备基于可定制规则的词法分析功能。
原理很简单,熟读 Python 文档的同学应该看过 regex module 帮助页面最下面有段程序:
def tokenize(code):
keywords = {'IF', 'THEN', 'ENDIF', 'FOR', 'NEXT', 'GOSUB', 'RETURN'}
token_specification = [
('NUMBER', r'\d+(\.\d*)?'), # Integer or decimal number
('ASSIGN', r':='), # Assignment operator
('END', r';'), # Statement terminator
('ID', r'[A-Za-z]+'), # Identifiers
('OP', r'[+\-*/]'), # Arithmetic operators
('NEWLINE', r'\n'), # Line endings
('SKIP', r'[ \t]+'), # Skip over spaces and tabs
('MISMATCH', r'.'), # Any other character
]
tok_regex = '|'.join('(?P<%s>%s)' % pair for pair in token_specification)
line_num = 1
line_start = 0
for mo in re.finditer(tok_regex, code):
kind = mo.lastgroup
value = mo.group()
column = mo.start() - line_start
if kind == 'NUMBER':
value = float(value) if '.' in value else int(value)
elif kind == 'ID' and value in keywords:
kind = value
elif kind == 'NEWLINE':
line_start = mo.end()
line_num += 1
continue
elif kind == 'SKIP':
continue
elif kind == 'MISMATCH':
raise RuntimeError(f'{value!r} unexpected on line {line_num}')
yield Token(kind, value, line_num, column)
上面这个官方文档里的程序,输入一段代码,返回 token 的:名称、原始文本、行号、列号 等。
它其实已经具备好三个重要功能了:1)规则自定义;2)由上往下匹配规则;3)使用生成器,逐步返回结果,而不是一次性处理好再返回,这个很重要,可以保证语法分析器边分析边指导词法分析器做一些精细化分析。
我们再它的基础上再修改一下,主要补充:
- 支持外部传入规则,而不是像上面那样写死的。
- 规则支持传入函数,这样可以根据结果进行二次判断。
- 更好的行和列信息统计,不依赖 NEWLINE 规则的存在。
- 支持 flex/lex 中的 “忽略”规则,比如忽略空格和换行,或者忽略注释。
- 支持在流末尾添加一个 EOF 符号,某些 parsing 技术需要输入流末尾插入一个名为 \$ 的结束符。
对文档中的简陋例子做完上面五项修改,我们即可得到一个通用的基于规则的词法分析器。
改写后代码很短,只有 56 行:
(点击 more 展开)
Read more…

前文《基于 LR(1) 和 LALR 的 Parser Generator》里介绍了春节期间开发的小玩具 LIBLR ,今天春节最后一天,用它跑一个小例子,解析带注释的 json 文件。由于 python 自带 json 库不支持带注释的 json 解析,而 vscode 里大量带注释的 json 没法解析,所以我们先写个文法,保存为 json.txt:
# 定义两个终结符
%token NUMBER
%token STRING
start: value {get1}
;
value: object {get1}
| array {get1}
| STRING {get_string}
| NUMBER {get_number}
| 'true' {get_true}
| 'false' {get_false}
| 'null' {get_null}
;
array: '[' array_items ']' {get_array}
;
array_items: array_items ',' value {list_many}
| value {list_one}
| {list_empty}
;
object: '{' object_items '}' {get_object}
;
object_items: object_items ',' item_pair {list_many}
| item_pair {list_one}
| {list_empty}
;
item_pair: STRING ':' value {item_pair}
;
# 词法:忽略空白
@ignore [ \r\n\t]*
# 词法:忽略注释
@ignore //.*
# 词法:匹配 NUMBER 和 STRING
@match NUMBER [+-]?\d+(\.\d*)?
@match STRING "(?:\\.|[^"\\])*"
有了文法,程序就很短了,50 多行足够:(点击 more 展开)
Read more…
最近处理文本比较多,先前想增强下正则,看来不够用了,有同学推荐了我 Pyl 和 Lark,看了两眼,初看还行,但细看有一些不太喜欢的地方,于是刚好春节几天有空,从头写了一个 LR(1) / LALR 的 Generator,只有一个 LIBLR.py 的单文件,没有其它依赖:
用法很简单,给定文法,返回 Parser:
import LIBLR
# 注意这里是 r 字符串,方便后面写正则
# 所有词法规则用 @ 开头,从上到下依次匹配
grammar = r'''
start: WORD ',' WORD '!';
@ignore [ \r\n\t]*
@match WORD \w+
'''
parser = LIBLR.create_parser(grammar)
print(parser('Hello, World !'))
输出:
Node(Symbol('start'), ['Hello', ',', 'World', '!'])
默认没有加 Semantic Action 的话,会返回一颗带注释的语法分析树(annotated parse-tree)。
支持语义动作(Semantic Action),可以在生成式中用 {name} 定义,对应 name 的方法会在回调中被调用:
import LIBLR
# 注意这里是 r 字符串,方便后面写正则
grammar = r'''
# 事先声明终结符
%token number
E: E '+' T {add}
| E '-' T {sub}
| T {get1}
;
T: T '*' F {mul}
| T '/' F {div}
| F {get1}
;
F: number {getint}
| '(' E ')' {get2}
;
# 忽略空白
@ignore [ \r\n\t]*
# 词法规则
@match number \d+
'''
# 定义语义动作:各个动作由类成员实现,每个方法的
# 第一个参数 rule 是对应的生成式
# 第二个参数 args 是各个部分的值,类似 yacc/bison 中的 $0-$N
# args[1] 是生成式右边第一个符号的值,以此类推
# args[0] 是继承属性
class SemanticAction:
def add (self, rule, args):
return args[1] + args[3]
def sub (self, rule, args):
return args[1] - args[3]
def mul (self, rule, args):
return args[1] * args[3]
def div (self, rule, args):
return args[1] / args[3]
def get1 (self, rule, args):
return args[1]
def get2 (self, rule, args):
return args[2]
def getint (self, rule, args):
return int(args[1])
parser = LIBLR.create_parser(grammar, SemanticAction())
print(parser('1+2*3'))
输出:
(点击 more 查看更多)
Read more…
正则写复杂了很麻烦,难写难调试,只需要两个函数,就能用简单正则组合构建复杂正则:
比如输入一个字符串规则,可以使用 {name} 引用前面定义的规则:
# rules definition
rules = r'''
protocol = http|https
login_name = [^:@\r\n\t ]+
login_pass = [^@\r\n\t ]+
login = {login_name}(:{login_pass})?
host = [^:/@\r\n\t ]+
port = \d+
optional_port = (?:[:]{port})?
path = /[^\r\n\t ]*
url = {protocol}://({login}[@])?{host}{optional_port}{path}?
'''
然后调用 regex_build 函数,将上面的规则转换成一个字典并输出:
# expand patterns in a dictionary
m = regex_build(rules, capture = True)
# list generated patterns
for k, v in m.items():
print(k, '=', v)
结果:
protocol = (?P<protocol>http|https)
login_name = (?P<login_name>[^:@\r\n\t ]+)
login_pass = (?P<login_pass>[^@\r\n\t ]+)
login = (?P<login>(?P<login_name>[^:@\r\n\t ]+)(:(?P<login_pass>[^@\r\n\t ]+))?)
host = (?P<host>[^:/@\r\n\t ]+)
port = (?P<port>\d+)
optional_port = (?P<optional_port>(?:[:](?P<port>\d+))?)
path = (?P<path>/[^\r\n\t ]*)
url = (?P<url>(?P<protocol>http|https)://((?P<login>(?P<login_name>[^:@\r\n\t ]+)(:(?P<login_pass>[^@\r\n\t ]+))?)[@])?(?P<host>[^:/@\r\n\t ]+)(?P<optional_port>(?:[:](?P<port>\d+))?)(?P<path>/[^\r\n\t ]*)?)
用手写直接写是很难写出这么复杂的正则的,写出来也很难调试,而组合方式构建正则的话,可以将小的简单正则提前测试好,要用的时候再组装起来,就不容易出错,上面就是组装替换后的结果。
下面用里面的 url 这个规则来匹配一下:
(点击 more 展开)
Read more…
知乎问题《什么时候用C而不用C++?》:
前两天不是有一个问题是“什么时候用C++而不用C”,我一直觉得问错了,难道不是“能用C++就不用C”么?那么当然就要讨论什么时候用C而不用C++啦。
一直以来都严格遵循OO的原则来进行开发(用的工具是C#和Qt),直到最近,开始接手某同事的代码,整个项目20多个小工程(代码量并不多),除了界面部分用了MFC这种不伦不类的OO以外,所有的代码都是C写的。但是模块化做的非常好。后来跟他讨论为何不用C++,他说其实没有什么特别的,就是习惯和爱好而已,后又补充:
如果不用多态的话,其实不管怎么写,不管用那种语言写,都算不上真正的OO
忽然觉得很有道理……
其实这是一个好问题,
题主开始欣赏到纯 C代码所带来的 “美感” 了,即简单性和可拆分性。代码是自底向上构造,一个模块只做好一个模块的事情,任意拆分组合。对于有参考的 OOP系统建模,自顶向下的构造代码抽象方法是有效率的,是方便的,对于新领域,没有任何参考时,刻意抽象会带来额外负担,并进一步增加系统耦合性,设计调整,往往需要大面积修改代码。
有兴趣你可以读读《Unix编程艺术》,OOP的思维模式,是大一统的;C的思维模式,是分离的。前者方便但容易造成高耦合,后者灵活但开发开发太累。用 C开发,应该刻意强调 “简单” 和 “可拆分”。一个个象搭积木一样的把基础系统搭建出来,哪个模块出问题,局部替换即可。
自底向上的开发模式,并不是从不站在大局考虑问题,而是从某个子系统具体实现开始,从局部迭代,逐步反思全局设计,刻意保持低偶合,一个模块一个模块的来,再逐步尝试组合。
自底向上强调先有实践,再总结理论,理论反过来指导实践,又从实践中迭代修正理论。这和人类认识世界的顺序是一样的,先捕猎筑巢,反思自然是怎么回事,又发现可以生火,又思考自然到底怎么回事情。
它的反面,是指大一统设计,你一开始用 UML画出整套系统的类结构,然后再开工设计。这种思维习惯,如果是参考已有系统做一个类似的设计,问题不大,全新设计的话,他总有一个前提,就是 “你能完整认识整个大自然”,就像人类一开始就要认识捕猎和筑巢还有取火一样。否则每次对世界有了新认识,OOP的自顶向下设计方法都能给你带来巨大的负担。
所以有些人才会说:OOP设计习惯会依赖一系列设计灵巧的 BaseObject,然而过段时间后再来看你的项目,当其中某个基础抽象类出现问题是,往往面临大范围的代码调整。这其实就是他们使用自顶向下思维方法,在逐步进入新世界时候,所带来的困惑。
当然也有人批判这种强调简单性和可拆分性的 Unix思维。认为世界不是总能保持简单和可拆分的,他们之间是有各种千丝万缕联系的,你一味的保持简单性和可拆分性,你会让别人很累。这里给你个药方,底层系统,基础组建,尽量用 C的方法,很好的设计成模块,随着你编程的积累,这些模块象积木一样越来越多,而彼此都无太大关系,甚至不少 .c文件都能独立运行,并没有一个一统天下的 common.h让大家去 include,接口其他语言也方便。
然后在你做到具体应用时根据不同的需求,用C++或者其他语言,将他们象胶水一样粘合起来。这时候,再把你的 common.h,写到你的 C++或者其他语言里面去。当然,作为胶水的语言不一定非要是 C++了,也可以是其他语言。
————-
PS: 这里主要在探讨 OOP存在的问题,并没有讨论嵌入式这种资源限制的情况,以及操作系统和底层等需要精确控制硬件和内存的情况,更没有讨论 C++在语言设计层面的事情。
————-
转部分答疑:(点击more展开)
Read more…
常用 MSVC写内嵌汇编需要兼容 GCC是一件头疼的事情,不是说你不会写 GCC的 AT&T风格汇编,而是说同一份代码写两遍,还要调试两遍,是一件头疼的事情,特别是汇编写了上百行的时候。于是五年前写过一个小工具,可以方便的进行转换,能把 MSVC/MASM的汇编转成纯 AT&T风格汇编,或者 GCC Inline风格汇编,自动识别寄存器和变量,还有跳转地址,并且自动导出。今天把他放上来,或许有用到的人吧。
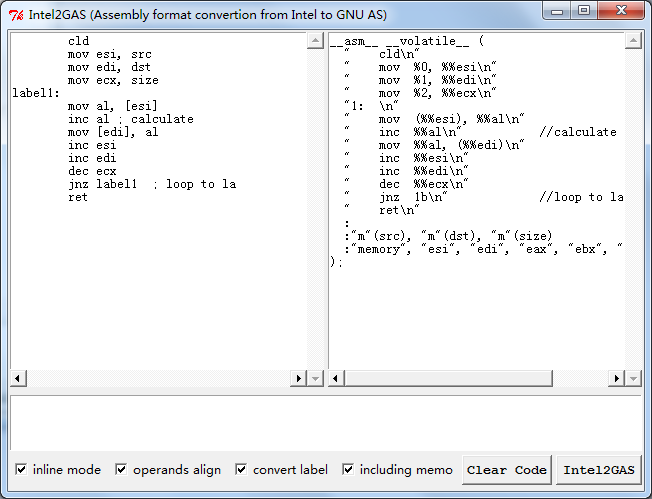
Read more…
用最简单的方法描述工程信息,简化gnumake的繁琐操作,让不会用gnumake的同学们彻底解脱:
项目地址:http://code.google.com/p/easymake/
实时动态在内存中编译汇编代码,并返回函数调用指针,可用于JIT系统的后端:
项目地址:http://code.google.com/p/asmpure/
例子:
const char *AlphaBlendAsm =
"PROC C1:DWORD, C2:DWORD, A:DWORD\n"
" movd mm0, A\n"
" punpcklwd mm0, mm0\n"
" punpckldq mm0, mm0\n"
" pcmpeqb mm7, mm7\n"
" psubw mm7, mm0\n"
" \n"
" punpcklbw mm1, C1\n"
" psrlw mm1, 8\n"
" punpcklbw mm2, C2\n"
" psrlw mm2, 8\n"
" \n"
" pmullw mm1, mm7\n"
" pmullw mm2, mm0\n"
" paddw mm1, mm2\n"
" \n"
" psrlw mm1, 8\n"
" packuswb mm1, mm1\n"
" movd eax, mm1\n"
" emms\n"
" ret\n"
"ENDP\n";
void testAlphaBlend(void)
{
CAssembler *casm;
int c;
int (*AlphaBlendPtr)(int, int, int);
// create assembler
casm = casm_create();
// append assembly source
casm_source(casm, AlphaBlendAsm);
AlphaBlendPtr = (int (*)(int, int, int))casm_callable(casm, NULL);
if (AlphaBlendPtr == NULL) {
printf("error: %s\n", casm->error);
casm_release(casm);
return;
}
printf("==================== Alpha Blend ====================\n");
casm_dumpinst(casm, stdout);
printf("\nExecute code (y/n)?\n\n");
do
{
c = getch();
}
while(c != 'y' && c != 'n');
if(c == 'y')
{
int x = AlphaBlendPtr(0x00FF00FF, 0xFF00FF00, 128);
printf("output: %.8X\n\n", x);
}
free(AlphaBlendPtr);
casm_release(casm);
}
output: 7f7f7f7f
Recent Comments