来个更短的,没有其他乱七八糟的东西,只有一个简短的 C文件,不需要 linux 环境:
miniboot.c
asm(".long 0x1badb002, 0, (-(0x1badb002 + 0))");
unsigned char *videobuf = (unsigned char*)0xb8000;
const char *str = "Hello, World !! ";
int start_entry(void)
{
int i;
for (i = 0; str[i]; i++) {
videobuf[i * 2 + 0] = str[i];
videobuf[i * 2 + 1] = 0x17;
}
for (; i < 80 * 25; i++) {
videobuf[i * 2 + 0] = ' ';
videobuf[i * 2 + 1] = 0x17;
}
while (1) { }
return 0;
}
编译:
gcc -c -fno-builtin -ffreestanding -nostdlib -m32 miniboot.c -o miniboot.o
ld -e start_entry -m elf_i386 -Ttext-seg=0x100000 miniboot.o -o miniboot.elf
运行:
qemu-system-i386 -kernel miniboot.elf
结果:

满足条件:
- 只用纯 C 开发,可以使用 gcc 编译
- 编译出来的东西真的可以运行
- 不需要依赖操作系统
- 不需要包含系统调用的 glibc
- 连 libgcc 都不需要
解释一下:
Read more…

哈希表性能优化的方法有很多,比如:
- 使用双 hash 检索冲突
- 使用开放+封闭混合寻址法组织哈希表
- 使用跳表快速定位冲突
- 使用 LRU 缓存最近访问过的键值,不管表内数据多大,短时内访问的总是那么几个
- 使用更好的分配器来管理 keyvaluepair 这个节点对象
上面只要随便选两条你都能得到一个比 unordered_map 快不少的哈希表,类似的方法还有很多,比如使用除以质数来归一化哈希值(x86下性能最好,整数除法非常快,但非x86就不行了,arm还没有整数除法指令,要靠软件模拟,代价很大)。
哈希表最大的问题就是过分依赖哈希函数得到一个正态分布的哈希值,特别是开放寻址法(内存更小,速度更快,但是更怕哈希冲突),一旦冲突多了,或者 load factor 上去了,性能就急剧下降。
Python 的哈希表就是开放寻址的,速度是快了,但是面对哈希碰撞攻击时,挂的也是最惨的,早先爆出的哈希碰撞漏洞,攻击者可以通过哈希碰撞来计算成千上万的键值,导致 Python / Php / Java / V8 等一大批语言写成的服务完全瘫痪。
后续 Python 推出了修正版本,解决方案是增加一个哈希种子,用随机数来初始化它,这都不彻底,开放寻址法对hash函数的好坏仍然高度敏感,碰到特殊的数据,性能下降很厉害。
经过最近几年的各种事件,让人们不得不把目光从“如何实现个更快的哈希表”转移到 “如何实现一个最不坏的哈希表”来,以这个新思路重新思考 hash 表的设计。
哈希表定位主要靠下面一个操作:
index_pos = hash(key) % index_size;
来决定一个键值到底存储在什么地方,虽然 hash(key) 返回的数值在 0-0xffffffff 之前,但是索引表是有大小限制的,在 hash 值用 index_size 取模以后,大量不同哈希值取模后可能得到相同的索引位置,所以即使哈希值不一样最终取模后还是会碰撞。
第一种思路是尽量避免冲突,比如双哈希,比如让索引大小 index_size 保持质数式增长,但是他们都太过依赖于哈希函数本身;所以第二种思路是把注意力放在碰撞发生了该怎么处理上,比如多层哈希,开放+封闭混合寻址法,跳表,封闭寻址+平衡二叉树。
优化方向
今天我们就来实现一下最后一种,也是最彻底的做法:封闭寻址+平衡二叉树,看看最终性能如何?能否达到我们的要求?实现起来有哪些坑?其原理简单说起来就是,将原来封闭寻址的链表,改为平衡二叉树:
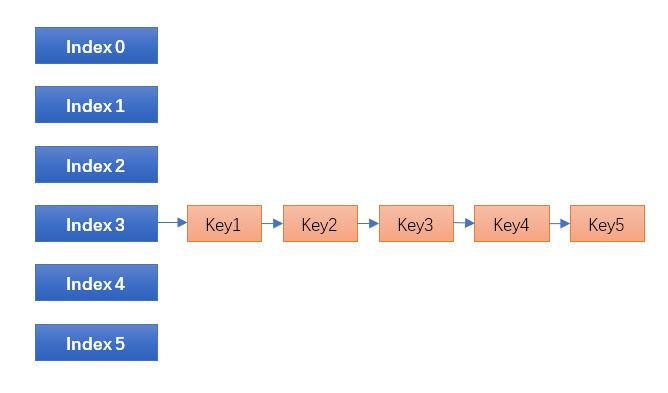
传统的封闭寻址哈希表,也是 Linux / STL 等大部分哈希表的实现,碰到碰撞时链表一长就挂掉,所谓哈希表+平衡二叉树就是:
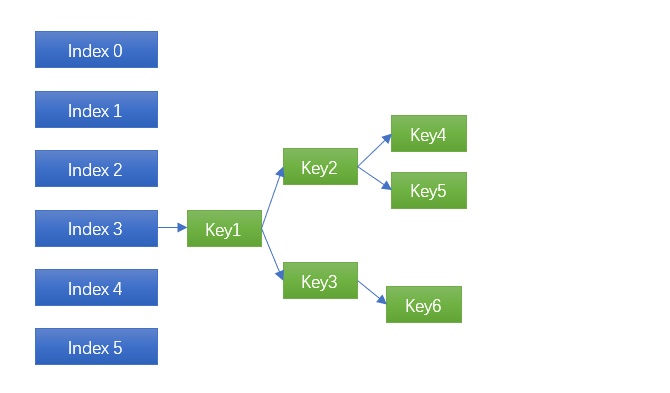
将原来的链表(有序或者无序)换成平衡二叉树,这是复杂度最高的做法,同时也是最可靠的做法。发生碰撞时能将时间复杂度由 O(N) 降低到 O(logN),10个节点,链表的复杂度就是 10,而使用平衡二叉树的复杂度是 3;100个节点前者的时间是100,后者只有6.6 越往后差距约明显。
面临问题
树表混合结构(哈希表+平衡二叉树)的方法,Hash table – Wikipedia 上面早有说明,之所以一直没有进入各大语言/SDK的主流实现主要有四个问题:
- 比起封闭寻址(STL,Java)来讲,节点少时,维持平衡(旋转等)会比有序链表更慢。
- 比起开放寻址(python,v8实现)来讲,内存不紧凑,缓存不够友好。
- 占用更多内存:一个平衡二叉树节点需要更多指针。
- 设计比其他任何哈希表都要复杂。
所以虽然早就有人提出,但是一直都是一个边缘方法,并未进入主流实现。而最近两年随着各大语言暴露出来的各种哈希碰撞攻击,和原有设计基本无力应对坏一些的情况,于是又开始寻求这种树表混合结构是否还有优化的空间。
先来解决第一个问题,如果二叉树节点只有3-5个,那还不如使用有序链表,这是公认的事实,Java 8 最新实现的树表混合结构里,引入了一个 TREEIFY_THRESHOLD = 8 的常量,同一个索引内(或者叫同一个桶/slot/bucket内),冲突键值小于 8 的,使用链表,大于这个阈值时当前 index 内所有节点进行树化操作(treeify)。
Java 8 靠这个方法有效的解决了第一个问题和第三个问题,最终代替了原有 java4-7 一直在使用的 HashMap 老实现,那么我们要使用 Java 8 的方法么?
不用,今天我们换种实现。
Read more…
网上对 AVL被批的很惨,认为性能不如 rbtree,这里给 AVL 树平反昭雪。最近优化了一下我之前的 AVL 树,总体跑的和 linux 的 rbtree 一样快了:
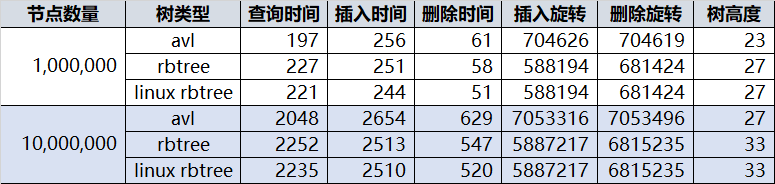
他们都比 std::map 快很多(即便使用动态内存分配,为每个新插入节点临时分配个新内存)。
项目代码在:skywind3000/avlmini
其他 AVL/RBTREE 评测也有类似的结论,见:STL AVL Map
谣言1:RBTREE的平均统计性能比 AVL 好
统计下来一千万个节点插入 AVL 共旋转 7053316 次(先左后右算两次),RBTREE共旋转 5887217 次,RBTREE看起来少是吧?应该很快?但是别忘了 RBTREE 再平衡的操作除了旋转外还有再着色,每次再平衡噼里啪啦的改一片颜色,父亲节点,叔叔,祖父,兄弟节点都要访问一圈,这些都是代价,再者平均树高比 AVL 高也成为各项操作的成本。
谣言2:RBTREE 一般情况只比 AVL 高一两层,这个代价忽略不计
纯粹谣言,随便随机一下,一百万个节点的 RBTREE 树高27,和一千万个节点的 AVL树相同,而一千万个节点的 RBTREE 树高 33,比 AVL 多了 6 层,这还不是最坏情况,最坏情况 AVL 只有 1.440 * log(n + 2) – 0.328, 而 RBTREE 是 2 * log(n + 1),也就是说同样100万个节点,AVL最坏情况是 28 层,rbtree 最坏可以到 39 层。
谣言3:AVL树删除节点是需要回溯到根节点
我以前也是这么写 AVL 树的,后来发现根据 AVL 的定义,可以做出两个推论,再平衡向上回溯时:
插入更新时:如当前节点的高度没有改变,则上面所有父节点的高度和平衡也不会改变。
删除更新时:如当前节点的高度没有改变且平衡值在 [-1, 1] 区间,则所有父节点的高度和平衡都不会改变。
根据这两个推论,AVL的插入和删除大部分时候只需要向上回溯一两个节点即可,范围十分紧凑。
谣言4:虽然二者插入一万个节点总时间类似,但是rbtree树更平均,avl有时很快,有时慢很多,rbtree 只需要旋转两次重新染色就行了,比 avl 平均
完全说反了,avl是公认的比rbtree平均的数据结构,插入时间更为平均,rbtree才是不均衡,有时候直接插入就返回了(上面是黑色节点),有时候插入要染色几个节点但不旋转,有时候还要两次旋转再染色然后递归到父节点。该说法最大的问题是以为 rbtree 插入节点最坏情况是两次旋转加染色,可是忘记了一条,需要向父节点递归,比如:当前节点需要旋转两次重染色,然后递归到父节点再旋转两次重染色,再递归到父节点的父节点,直到满足 rbtree 的5个条件。这种说法直接把递归给搞忘记了,翻翻看 linux 的 rbtree 代码看看,再平衡时那一堆的 while 循环是在干嘛?不就是向父节点递归么?avl和rbtree 插入和删除的最坏情况都需要递归到根节点,都可能需要一路旋转上去,否则你设想下,假设你一直再树的最左边插入1000个新节点,每次都想再局部转两次染染色,而不去调整整棵树,不动根节点,可能么?只是说整个过程avl更加平均而已。
比较结论
Read more…
应用层用spinlock的最大问题是不能跟kernel一样的关中断(cli/sti),假设并发稍微多点,线程1在lock之后unlock之前发生了时钟中断,一段时间后才会被切回来调用unlock,那么这段时间中另一个调用lock的线程不就得空跑while了?这才是最浪费cpu时间的地方。所以不能关中断就只能sleep了,怎么着都存在巨大的冲突代价。
尤其是多核的时候,假设 Kernel 中任务1跑在 cpu1上,任务 2跑在 cpu2上,任务1进入lock之前就把中断关闭了,不会被切走,调用unlock的时候,不会花费多少时间,cpu2上的任务2在那循环也只会空跑几个指令周期。
看看 Kernel 的 spinlock:
#define _spin_lock_irq(lock) \
do { \
local_irq_disable(); \
preempt_disable(); \
_raw_spin_lock(lock); \
__acquire(lock); \
} while (0)
看到里面的 local_irq_disable() 了么?实现如下:
#define local_irq_disable() \
__asm__ __volatile__("cli": : :"memory")
倘若不关闭中断,任务1在进入临界区的时候被切换走了,50ms以后才能被切换回来,即使原来临界区的代码只需要0.001ms就跑完了,可cpu2上的任务2还会在while那里干耗50ms,所以不能禁止中断的话只能用 sleep来避免空跑while浪费性能。
所以不能关闭中断的应用层 spinlock 是残废的,nop都没大用。
不要觉得mutex有多慢,现在的 mutex实现,都带 CAS,首先会在应用层检测冲突,没冲突的话根本不会不会切换到内核态,直接用户态就搞定了,即时有冲突也会先尝试spinlock一样的 try 几次(有限次数),不行再进入休眠队列。比傻傻 while 下去强多了。
C++ 不是号称不限制你的开发方式么,每个库想怎么搞就怎么搞,这明明就是 C++的优势,不知道大家抱怨个啥?哈哈
接着说 std::string 的性能问题,举个具体例子吧,之前接手过一个项目,别的部门同事自己撸的一套 DirectUI 系统,用 tinyxml 解析界面节点,项目简单的时候没啥,随着ui越来越复杂,数千个节点,每个xml节点若干属性,每个属性就是一个字符串,我记得好像有500+ KB的 xml要解析,而且这部分界面还没法延迟初始化,必须启动加载时做完,启动十分慢。profile下来,很多时间卡在 tinyxml上,整个过程接近 3秒,费时最前的操作卡在处理各种字符串的操作上。
把 tinyxml 换成其他 xml库 ?没那么容易,项目各处模块都在依赖 tinyxml的各种接口和类。一开始觉得内部的 TiXmlString 实现有问题,换成 std::string,vc 2012下时间从3秒增加到4秒,更不靠谱(vs2012应该已经有所谓SSO了),所以人家 tinyxml 这里用自己的 TiXmlString 肯定也是比较过的,不然干嘛不用 std::string 。
Read more…
如果要随便学学,便于日后使用那花两个星期买本书,配合网上文章就行了。
如果你想自己动手改 x264,为其添加一些你想要的东西,那么下面步骤你得耐心走完:
1: JPEG编码不但要学,还要自己实现,这是图像编码的基础,理解下yuv, dct, 量化,熵编码(不用参考 libjpeg,太庞大,建议参考 tinyjpeg.c,单文件)
2: MPEG2编码要学,现代编码器都是 block based 的,而 block based编码器的祖先就在MPEG2,理解下帧内编码,帧间预测,运动矢量,残差图等基础概念。具体代码可以看早期版本的 ffmpeg 的 avcodec,比如 mpeg12enc.c 代码也就1000多行,容易看,不过其中牵扯很多ffmpeg的内部数据结构,比如 picture, DCTELEM,各种 table,bitstream,vlc, swscale 等公共模块,缺点是文档少,优点是读了这些对你读其他 ffmpeg代码有帮助。
3: 自己实现一个类 MPEG2 编码器,最好自己从头实现个编码器,具体实现方式可以参考我的上面提到的 “视频编码技术简介”。
4: 参照 MPEG2的原理阅读 h.264的相关文章和书籍,了解和MPEG2的异同,比如先从intra入手,并且阅读 x264的早期版本代码,比如 2005年的版本,重点阅读 common 目录,基本的数据结构都在那里了,基本的图像,宏块,预测等都在那里了,阅读完以后阅读 encoder目录,了解程序的结构,2005版本的 x264是今天 x264的基础。
5: 阅读最新的 x264代码,并整理代码脉络,了解近年来引入的各种优化方法,然后 google, google, google …….
6: 愉快的修改 x264吧,比如增加搜索强度,修改预测范围,增加抗丢包特性,或者增加带内编码冗余,修改内部缓存策略,寻找降低编码延迟的方法,根据你的需求,修改,测试,修改,测试。。。。。。
7: 至于 MPEG4文件格式,可看可不看,一下午的事情。
参考阅读:
视频编码器原理简介
先前写过《视频编码原理简介》,有朋友问光代码和文字不太真切,能否补充几张图片,今天我们演示一下:
这是第一帧画面:P1(我们的参考帧)

这是第二帧画面:P2(需要编码的帧)

从视频中截取的两张间隔1-2秒的画面,和实际情况类似,下面我们参考P1进行几次运动搜索:
搜索演示1:搜索P2中车辆的车牌在P1中最接近的位置(上图P1,下图P2)

这是一个演示程序,鼠标选中P2上任意16×16的Block,即可搜索出P1上的 BestMatch 宏块。虽然车辆在运动,从远到近,但是依然找到了最接近的宏块坐标。
(点击 more 阅读剩下内容)
Read more…
今天继续在原来内存拷贝代码上优化:
1. 修改了小内存方案:由原来64字节扩大为128字节,由 int 改为 xmm,小内存性能提升 80%
2. 修改了中内存方案:从4个xmm寄存器并行拷贝改为8个并行拷贝+prefetch,提升20%左右
3. 去除目标地址头部对齐的分支判断,用一次xmm拷贝完成目标对齐,性能替升10%。
4. 增加测试用例:为贴近实际,增加了随机访问,10MB空间内(绝对大于L2尺寸)随机位置和长度的测试
为避免随机数生成影响结果,提前生成随机数,最终平均性能达到gcc4.9配套标准库的2倍以上:
https://github.com/skywind3000/FastMemcpy
最新代码测试结果(可以对比老的表看新版本性能是否有所提升):
Read more…



Recent Comments